1 复现笔记
1 创建Dateset
核心函数包括:init,getitem,len
-
init函数负责从磁盘中load指定格式的文件,计算并存储为特定形式 -
getitem函数负责在运行时提供给网络一次训练需要的输入,以及 groundtruth 的输出例如对NeRF,分别是1024条 rays 以及1024个 RGB 值
-
len函数是训练或者测试的数量:getitem函数获得的index值通常是[0, len-1]
1.1 __init__
这里我们主要要做3件事(公平公平还是tmd公平)
-
加载图像数据和相机位姿信息:
-
从磁盘中读取指定格式的文件,这些文件包含了图像路径和相机位姿信息,位姿保存在
self.poses -
从图片路径保存图片,并根据参数进行处理(白色背景+缩放比例)
-
最后,将处理后的图像添加到
self.images列表中
-
-
计算相机内参:
- 根据相机的视场角(FOV)和图像尺寸计算相机的焦距和相机矩阵
-
生成射线数据:
-
首先,对于每一个位姿,使用
rh.get_rays_np函数生成射线,并将所有射线堆叠起来 -
然后,将射线和图像数据合并,并进行一系列的变换和重塑操作形成形状为
[N, H, W, ro+rd+rgb, 3]的numpy数组rays_rgb-
N是图像的数量 -
H是图像的高度 -
W是图像的宽度 -
ro+rd+rgb表示每个射线的数据,包括射线的起始点(ro)、射线的方向(rd)和射线对应的像素颜色(rgb) -
3表示每个数据都是一个三维向量(例如,rgb颜色是一个三维向量,包含红色、绿色和蓝色的强度)
表示有
N*H*W条射线,每条射线有3个数据(ro、rd、rgb),每个数据都是一个三维向量 -
-
存储打乱前的射线
img_rays_rgb, 一张一张图片存储的,没有整合在一起 ,形状为[N, H*W, ro+rd+rgb, 3],再转换为 Tensor
-
1.2 __getitem__
1.2.1 训练数据
主要功能是负责在运行时提供给网络一次训练需要的输入,以及 groundtruth 的输出 —— N_rays条rays和N_rays个RGB值 ( N_rays = 1024)
-
将所有的光线(rays)和对应的RGB值整合到一个数组中,然后将这个数组的形状从
[N, H, W, ro+rd+rgb, 3]改变为[-1, 3, 3],即将所有的光线和RGB值平铺到一个一维数组中得到[N*H*W, ro+rd+rgb, 3],并转为 Tensor -
对所有的光线和RGB值进行打乱,这里使用GPU加速了一下
-
打乱后,根据索引
index选择一个批次(1024条)的数据,再将批次的维度从第二位转换到第一位([1024,3,3]to[3,1024,3])在PyTorch中,通常希望批次维度在第一位,以便于进行批次处理
-
将选择的数据分为两部分:光线的数据(
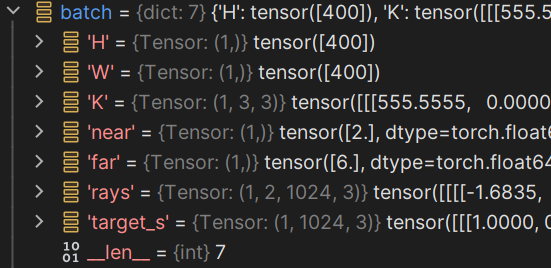
batch_rays)和对应的RGB值(target_s),并以字典的形式返回return {'H': self.H, 'W': self.W, 'K': self.K, 'near': self.near, 'far': self.far, 'rays': batch_rays, 'target_s': target_s}
1.2.2 测试数据
在测试时,输出一张图像的 rays 和 RGB 值,即 400 * 400 条 rays 和 400 * 400 个 RGB 值
-
从
self.img_rays_rgb中根据索引index获取一张图片的光线 -
使用
torch.transpose函数将批次的维度从第二位转换到第一位([1024,3,3]to[3,1024,3])在PyTorch中,通常希望批次维度在第一位,以便于进行批次处理
-
将数据分解为射线数据
rays和对应的RGB值img_rgb;rays包含了每条射线的起始点和方向,img_rgb是每条射线对应的RGB值 -
返回一个字典,包含了射线数据和对应的RGB值,以及对应的图片索引
indexreturn {'H': self.H, 'W': self.W, 'K': self.K, 'near': self.near, 'far': self.far, 'rays': rays, 'target_s': img_rgb, 'index': index}
通过data_loader我们可以得到一个batch:
-
train:
-
test:
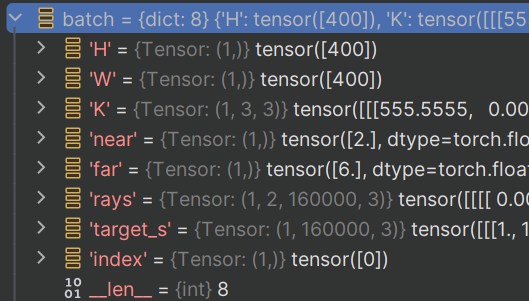
1.3 __len__
返回数据集的大小,即数据集中的样本数量,即图像的数量
2 Network
核心函数包括:__init__,__forward__
-
init函数负责定义网络所必需的模块 -
forward函数负责接收Dataset的输出,利用定义好的模块,计算输出
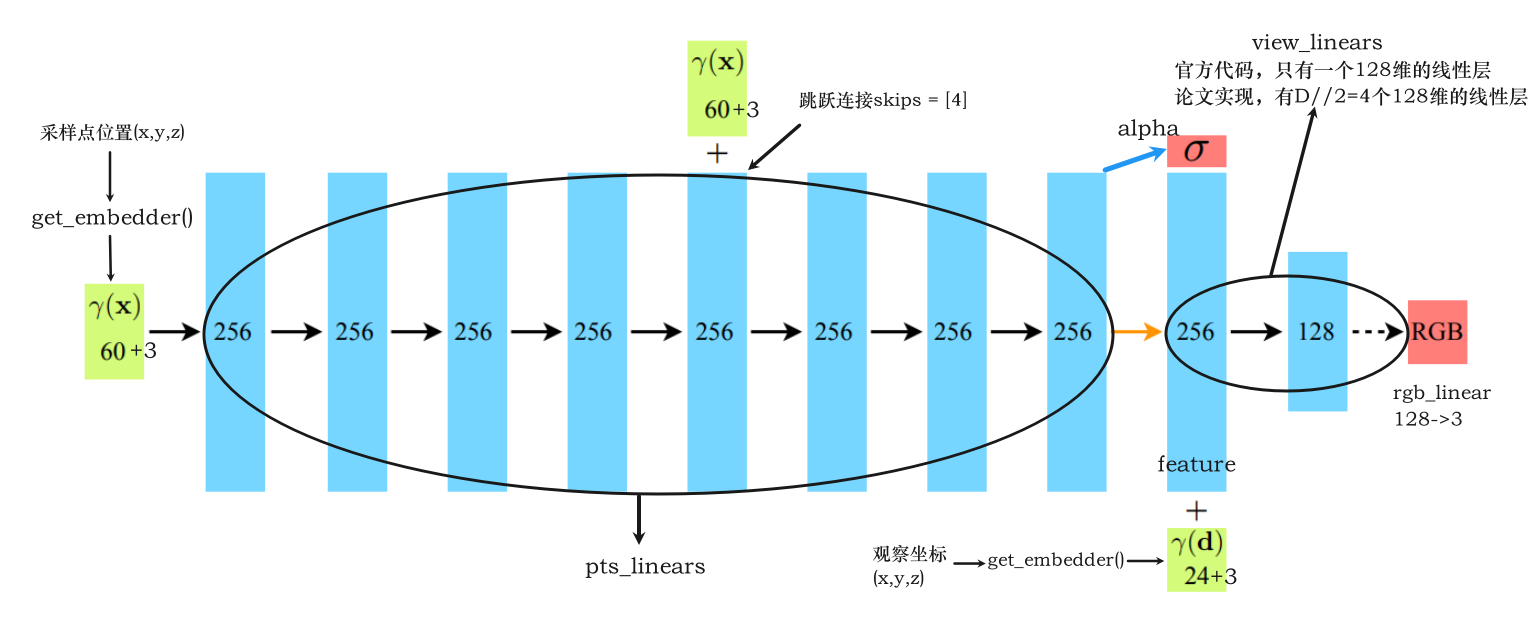
对于NeRF来说,我们需要在init中定义两个 MLP 以及 encoding 方式,在forward函数中,使用rays完成计算
定义了两个主要的神经网络模型:NeRF 和 Network
2.1 NeRF 类
NeRF 类是NeRF的实现。它的结构包括了用于处理采样点和观察坐标方向的一系列MLP,以及相应的参数。主要方法是 forward,用于执行前向传播操作
-
结构
-
__init__方法中定义了模型的各种参数和MLP -
forward方法实现了模型的前向传播逻辑,分别计算了辐射值和密度值,返回output——将rgb和alpha两个张量在最后一个维度上进行拼接outputs = torch.cat([rgb, alpha], -1)
-
2.2 Network 类
Network 类是整个神经网络的集成,其中包括了对 NeRF 模型的调用以及render的实现,完成模型的调用和计算模型产生的预估值(即在这部分完成渲染)
-
结构
-
__init__方法中初始化了整个网络模型,包括定义了两个NeRF模型(一个粗网络和一个精细网络),并根据配置参数进行设置 -
batchify方法用于将函数应用于较小的批次数据 -
network_query_fn方法,即网络查询函数,准备输入并将其传递给网络,并输出结果,使用batchify将一批一批的数据传入NeRF网络进行forward -
forward方法,从batch中得到dataloader的数据,调用render函数:- 计算并创建射线,使用
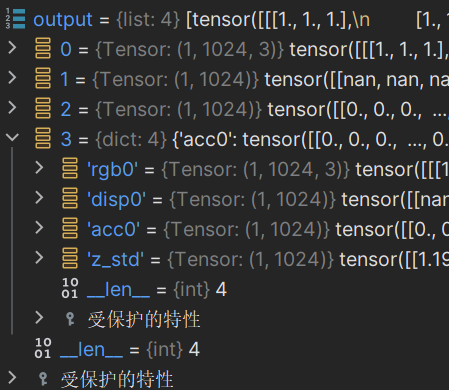
render_utils中的batchify_rays进行放入网络得到结果,再渲染射线得到render_rays返回的字典(即最后的结果):
- 'rgb_map' (torch.Tensor): 每条光线的估计 RGB 颜色。形状:[num_rays, 3]。 - 'disp_map' (torch.Tensor): 每条光线的视差图(深度图的倒数)。形状:[num_rays]。 - 'acc_map' (torch.Tensor): 沿每条光线的权重总和。形状:[num_rays]。 - 'rgb0' (torch.Tensor): 粗模型的输出 RGB。见 rgb_map。形状:[num_rays, 3]。 - 'disp0' (torch.Tensor): 粗模型的输出视差图。见 disp_map。形状:[num_rays]。 - 'acc0' (torch.Tensor): 粗模型的输出累积不透明度。见 acc_map。形状:[num_rays]。 - 'z_std' (torch.Tensor): 每个样本沿光线的距离的标准差。形状:[num_rays]。再对结果进行整理得到一个列表
- 计算并创建射线,使用
-
通过dataloader的batch传入网络,最终得到整理后的结果:
一个包含了所有渲染结果和相关信息的列表
前面 0、1、2 对应 'rgb_map'、'disp_map'、'acc_map'
所有张量类型如下
dtype = torch.float64
device = device(type='cuda', index=0)
2.3 Render
增加 render_utils,并修改 raw2outputs()、render_rays() 函数使数据移动至 cuda 进行计算
3 Loss & Evaluate
3.1 Loss
loss 模块主要为 NetworkWrapper 的类。forward 方法即是 loss 计算的过程。
- 方法中,首先通过
self.net(batch)调用传入的神经网络模型进行预测 - 然后计算预测的RGB值与目标RGB值之间的MSE,并将其转换为PSNR。如果输出中包含rgb0(即包含粗网络预测的值),则还会计算粗网络的预测值RGB与目标RGB值之间的MSE和PSNR。
- 最后,将所有的统计量(包括PSNR和损失)添加到scalar_stats字典中,并返回。
3.2 Evaluate
evaluate 模块在这个项目中主要用于评估模型的性能。并将评估结果保存为图像文件和JSON文件。
- 首先从模型的输出和批次数据中获取预测的RGB值和真实的RGB值
- 计算均方误差(MSE)和峰值信噪比(PSNR)
- 将预测的RGB值和真实的RGB值重塑为图像的形状。再将真实的RGB值和预测的RGB值水平拼接在一起,并保存为图像,形成对比
2 Issues
2.1 DataLoader 的多进程 pickle
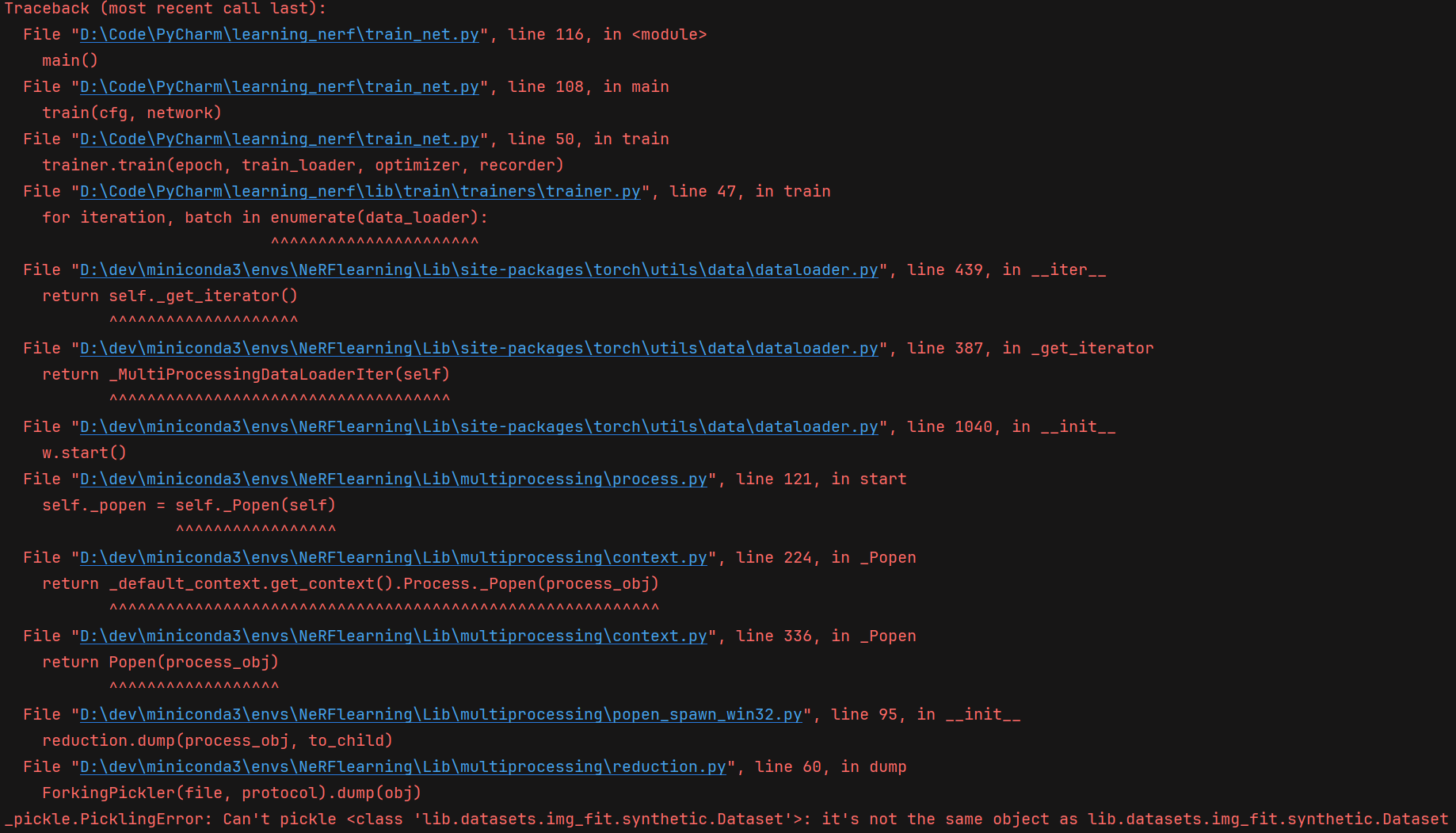
在刚开始执行时就遇到了这个错误,开始以为是环境问题,结果鼓捣半天没用,仔细分析了一下错误原因,发现主要是这句话的原因
for iteration, batch in enumerate(data_loader):
也就是序列化的问题,后面还给出了多进程的保持,就应该是多进程的pickle问题,网上一搜,还真是,可能是Windows系统的原因导致的,在 configs 中的配置文件中修改 num_workers = 0,不使用多进程,就解决了报错
2.2 imageio 输出图片
在执行到 evaluate 时,输出图片出了下面的错误:
envs\NeRFlearning\Lib\site-packages\PIL\Image.py", line 3102, in fromarray raise TypeError(msg) from e TypeError: Cannot handle this data type: (1, 1, 3), <f4
这是因为imageio.imwrite函数需要接收的图像数据类型为uint8,而原始的 pred_rgb 和 gt_rgb 可能是浮点数类型的数据。因此,我们需要将它们乘以255(将范围从0-1转换为0-255),然后使用 astype 函数将它们转换为 uint8 类型
# 将数据类型转换为 uint8
pred_rgb = (pred_rgb * 255).astype(np.uint8)
gt_rgb = (gt_rgb * 255).astype(np.uint8)
# 需要添加以上两行,否则报错
imageio.imwrite(save_path, img_utils.horizon_concate(gt_rgb, pred_rgb))
这里还有一个问题,我发现在已经生成过一张图片后,再次执行到这里,输出的新图片无法覆盖之前的旧图片,所以我加上了时间和当前周期作为扩展名
now = datetime.datetime.now()
now_str = now.strftime('%Y-%m-%d_%Hh%Mm%Ss')
base_name, ext = os.path.splitext(save_path)
save_path = f"{base_name}_{now_str}_epoch_{cfg.train.epoch}{ext}"
这样就会以这样的 res_2024-03-18_09h09m40s_epoch_10.jpg 格式正确输出每次的图像了
2.3 I/O
此项目是由 Linux 开发的,在Windows系统上,免不了出现各种麻烦。特别是,该项目的所有 I/O 都是 Linux 的 I/O 格式,所以要进行全面修改:
-
使用 Python 的 os 模块中的
makedirs函数来替换os.system('mkdir -p ' + model_dir) # | # V os.makedirs(model_dir, exist_ok=True) -
shutil模块中的rmtree函数来替换os.system('rm -rf {}'.format(model_dir)) # | # V import shutil if os.path.exists(model_dir): shutil.rmtree(model_dir) -
Python 的 os 模块中的
remove函数来替换os.system('rm {}'.format(os.path.join(model_dir, '{}.pth'.format(min(pths))))) # | # V os.remove(os.path.join(model_dir, '{}.pth'.format(min(pths)))) -
使用
exit(0)来结束当前进程os.system('kill -9 {}'.format(os.getpid())) # | # V exit(0)
2.4 evaluate 推理显存爆炸
在运行 evaluate 模块时,我用模型对一张图片进行推理,发现显存爆炸增长,经过一番寻找之后,找到了问题:
- 在运行 run.py 的 evaluate 模块时,
evaluator.evaluate(output, batch)这句话没有在torch.no_grad()中导致的。
修改只需要加一个缩减即可:
for i, batch in enumerate(tqdm.tqdm(data_loader)):
for k in batch:
if k != 'meta':
batch[k] = batch[k].cuda()
with torch.no_grad():
torch.cuda.synchronize()
start_time = time.time()
output = network(batch)
torch.cuda.synchronize()
end_time = time.time()
net_time.append(end_time - start_time)
if i == len(data_loader) - 1:
evaluator.evaluate(output, batch)
evaluator.summarize()
更新:重构了evaluate的代码,之前是我理解出现了问题,在evaluate中再一次进行了模型推理,现在不用了,代码恢复为以前的
2.5 训练问题
2.5.1 尝试一
训练中:在 Dateset 的 __getitem__ 函数中进行 shuffle,导致每次迭代都会 shuffle 整个数据一次,耗费大量时间
-
在经过10000次迭代(20个epoch)后:
-
psnr 整体是呈现一个上升的趋势,在10000次迭代后在24左右
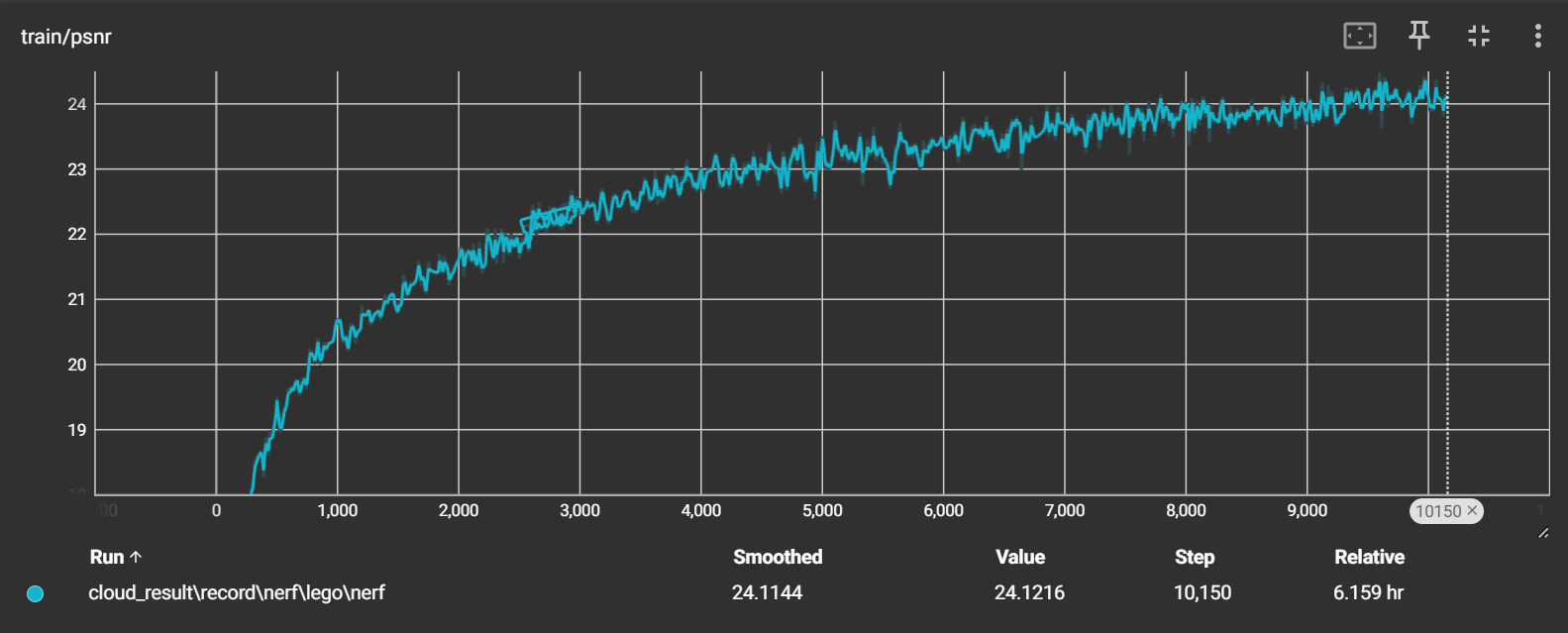
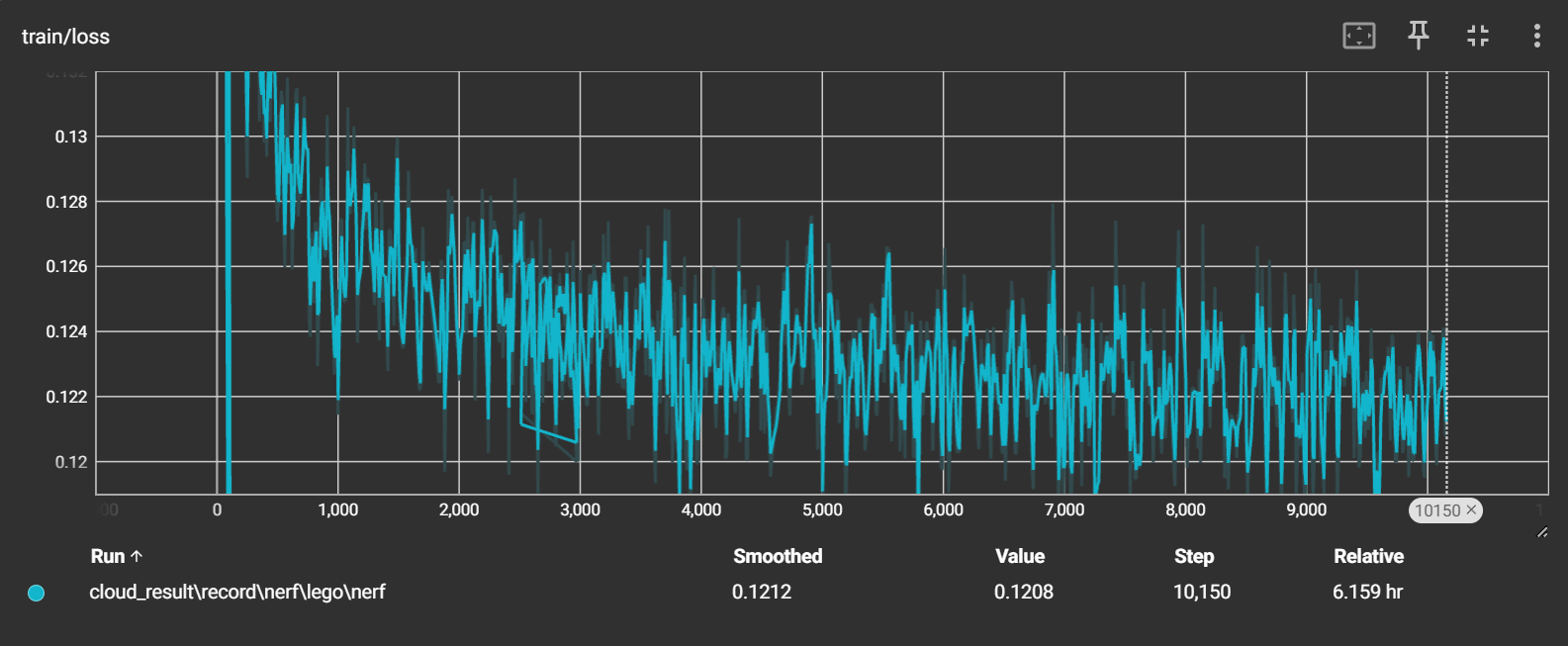
-
loss 从一开始整体下降,之后就一直在0.1225左右徘徊(感觉出现问题)没有明显的下降趋势
-
-
分别在5000次和10000次迭代的时候 evaluate 了两次:
- 第一次:loss = 0.1201,psnr = 22.94,mse = 0.005223
- 第二次:loss = 0.1191,psnr = 23.8,mse = 0.004276
推理得到的图像如下:

其实在训练时获取光线时本来就是打乱了的,传入
__getitem__的index就是随机的,但是发现在移除所有光线的 shuffle 后,训练出现问题(一直psnr = inf,loss = 0),具体原因还未知、
2.5.2 尝试二
现在我将 shuffle 放到了 __init__ 中去,只在创建数据集时进行一次 shuffle,训练正常进行,时间相比以前有了提升!
但出过拟合问题!
-
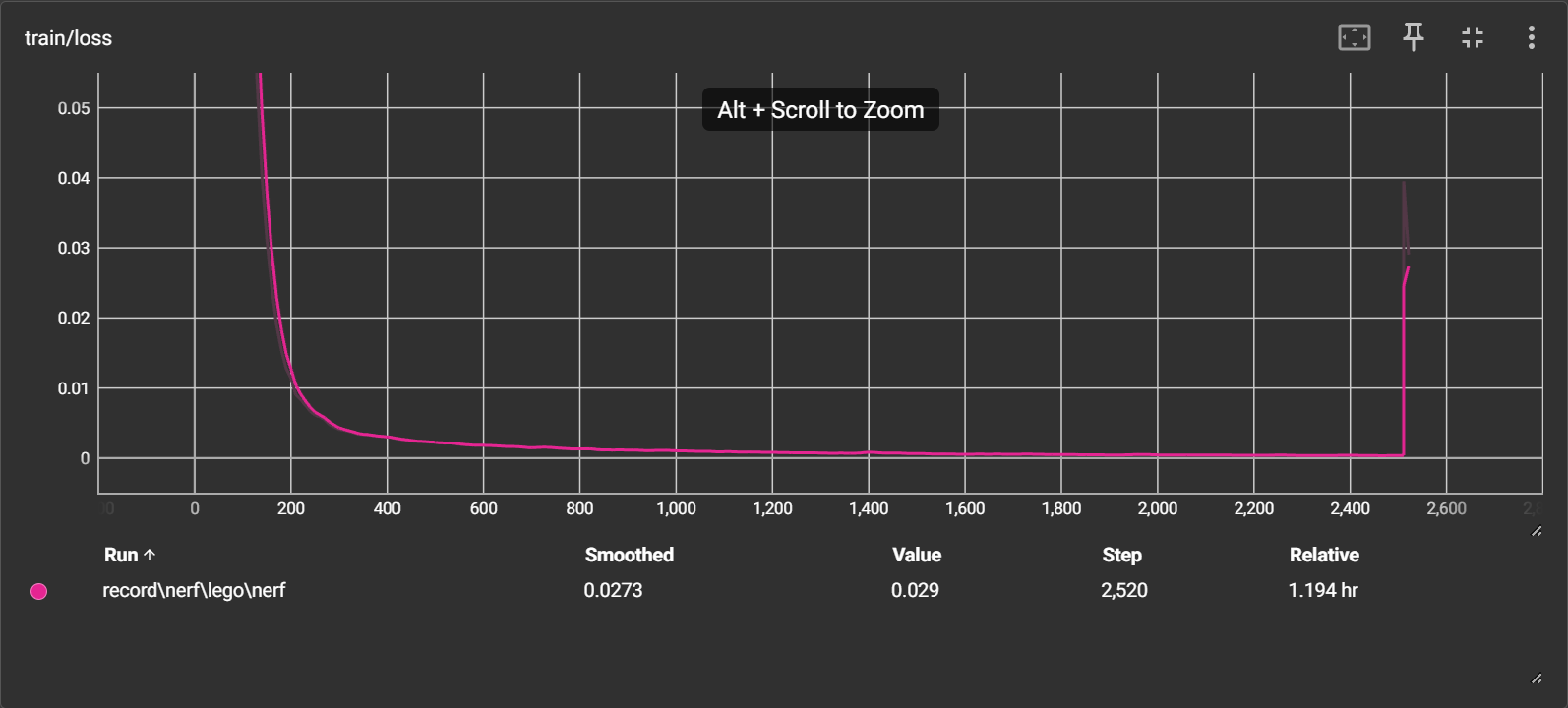
在2500次迭代(5个epoch)后:
-
loss 持续下降到 0.000292,停止后再次开始训练时断崖上升
-
psnr 持续上升到40,停止后再次开始训练时断崖下降
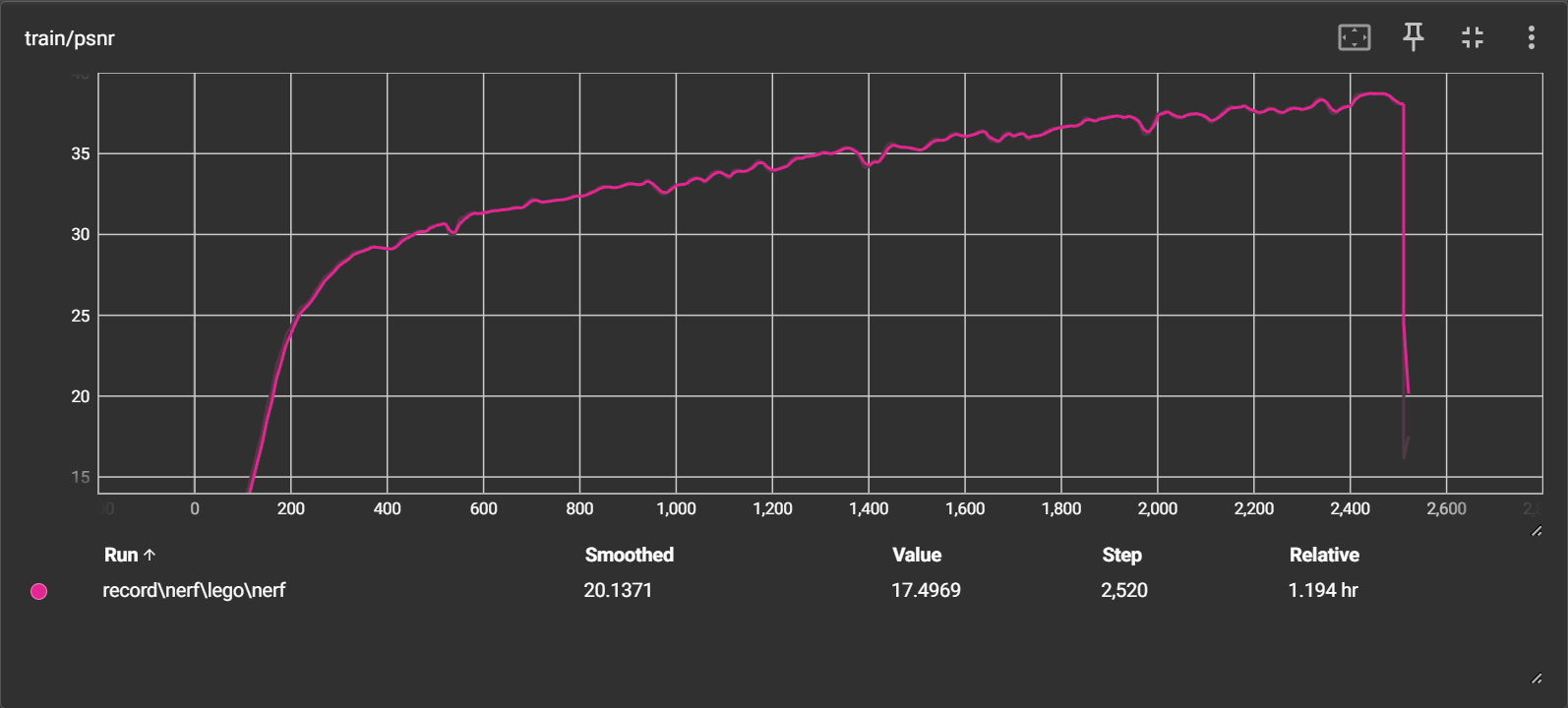
-
-
使用 run.py 的 evaluate 模块进行测试:
输出的图像与指标不符,loss = 0.055,psnr = 15.4939,mse = 0.0282;具体生成图像也是比较糟糕,只能看到大致雏形

问题:
发现了问题出现在数据集的 __getitem__ 上,每次传入的 index 是随机图片索引,只有只有 1~200,只能得到前面的 1~200*1024 的数据太狭隘了,导致了过拟合。
目前解决方案在 index 的基础上乘上图像的宽高:
index = index * self.H * self.W
2.5.3 尝试三
经过上述的修改,并且参考 nerf-pytorch 的代码在每隔一段时间(我现在暂时设定self.N_rays * cfg.ep_iter 次,即 1024*500)就会重新打乱一遍所有的32000000条光线
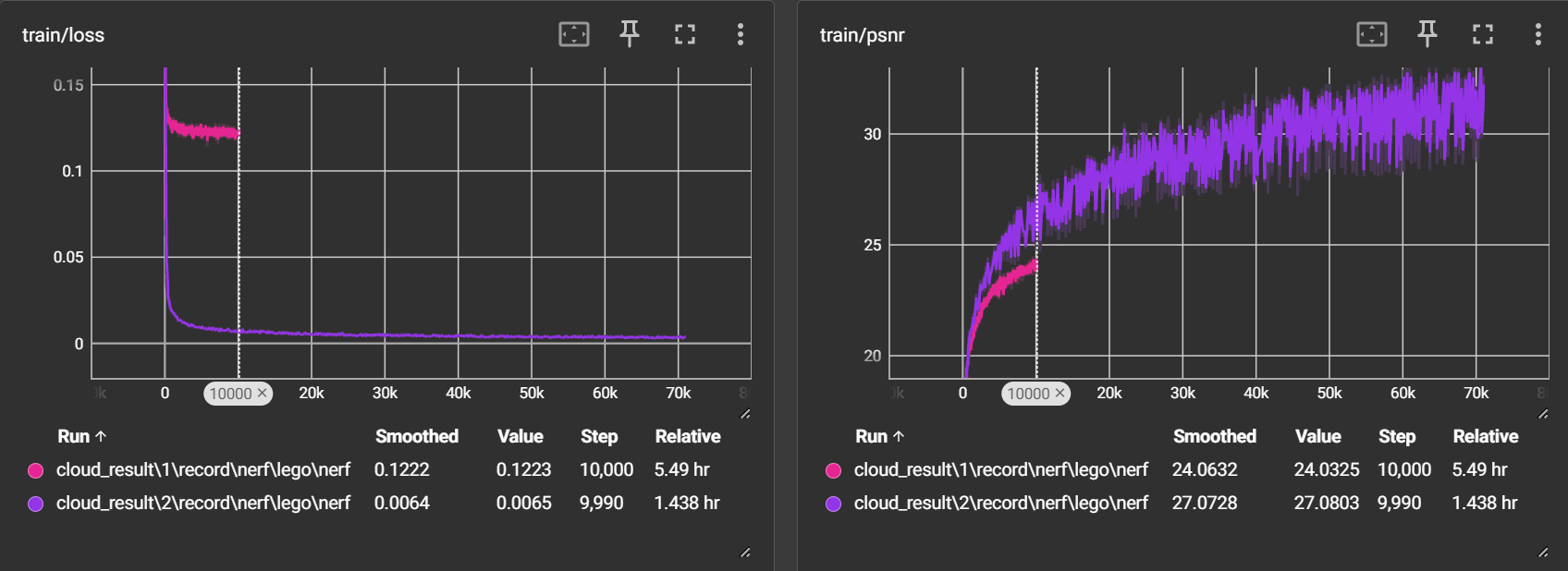
我将代码放到了阿里云的服务器上进行训练,经过10.48小时的训练,总共迭代了71,000次(142个epoch)
-
训练:
-
loss 持续下降,目前在0.003左右波动
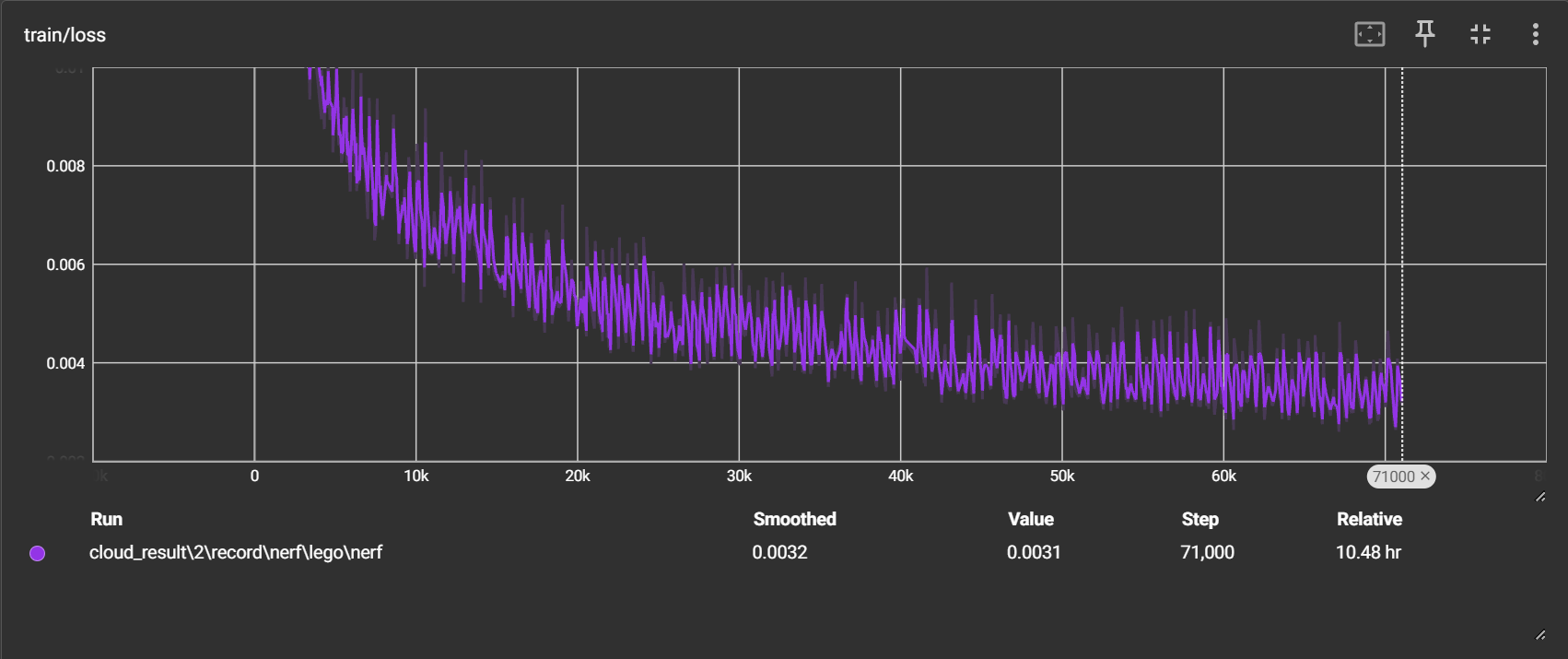
-
psnr 持续上升,目前在32左右波动
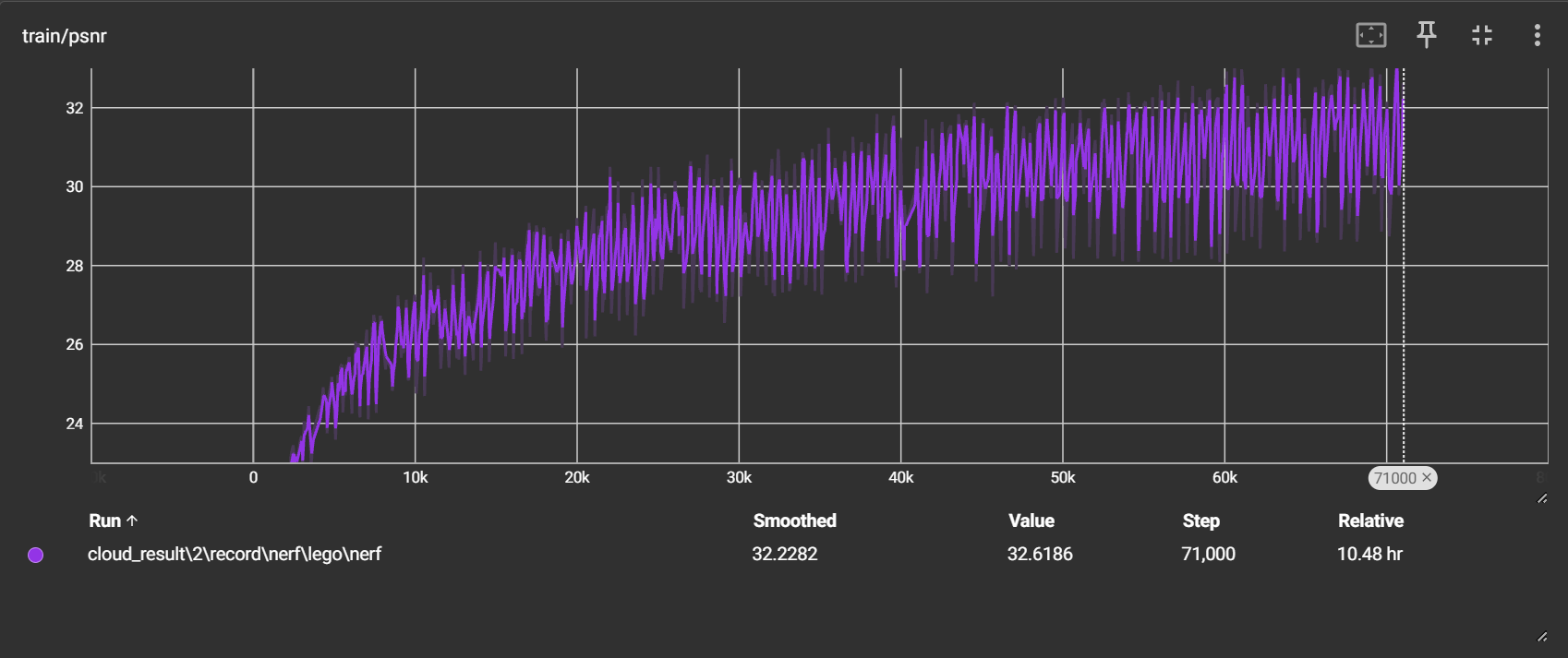
-
-
evaluate:我设定了每隔2500次迭代(5个epoch)就进行一次 evaluate,每次为了节省时间只用10张图片进行测试
loss 持续下降到0.006,mse 持续下降到0.0018,psnr 持续上升到27.6134
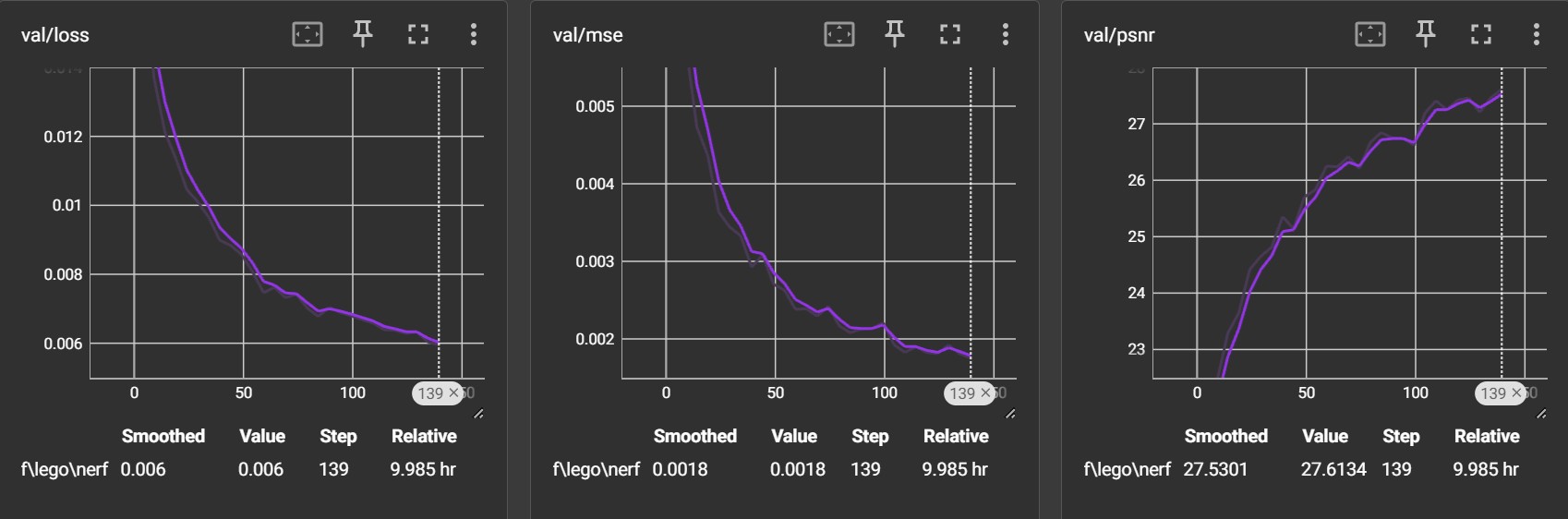
得到的图片:

训练完后对整体(200张图片)进行了一次 evaluate:得到 psnr = 28.4860
-
与尝试一进行对比:在10000次迭代左右,时间大大减少,且loss、psnr都更加优秀
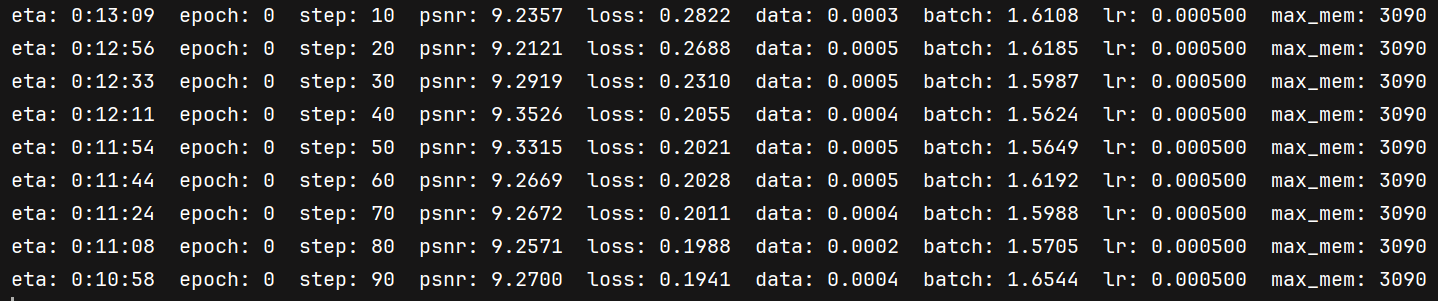
2.5.4 问题
有时开始训练时的psnr从9左右开始就会导致 psnr 不上升一直徘徊在9左右,loss 正常下降,重新开始训练就有可能回归正常!
尝试了5000次的迭代(10个epoch),测试出来图片如下:

目前原因未知😭