T2I-R1 学习笔记
1 Overview
https://arxiv.org/pdf/2505.00703
将语言模型中的 CoT 推理机制与 RL 方法引入图像生成领域
- 图像生成不仅需要理解文本(prompt)含义,还要实现跨模态的、逐像素的细节合成
- 如何协调语义级和像素级的推理过程,是当前生成模型难以解决的问题
整体是基于 Janus-Pro 这样的 Unified Generation and Understanding LMM
双层 CoT 机制(Bi-Level Chain-of-Thought)
论文提出了图像生成中的两个推理层级:
- 语义级 CoT:在图像生成前,通过对 prompt 进行深度理解与推理,规划图像的整体结构、物体布局等;本质是一个高层次的语言推理过程
- Token 级 CoT:在生成阶段,以 patch 为单位逐步生成图像的每个局部细节;等同于视觉版的逐步推理,处理细节、像素间连续性
Semantic-level CoT 就是相当于优化原始 prompt
这个 Token-level CoT ≈ 连续 image tokens, 其实还是相当于是生成图片进行优化,甚至还不如上一篇 Can We Generate Images with CoT 有推理的感觉,他这里的 CoT 就是指的连续的 image tokens 呗(没有思维的感觉)
- 不是显式的 reasoning chain(比如“为了生成这只猫,我先想它在沙发上、然后想颜色……”这种 step-by-step 思考)
- 也没有中间 token 做显式 planning、修改或校准
- 只是将自然存在的 token-by-token decoding 当作“CoT”,在训练阶段通过 reward 选择“好”的 tokens
它的真正贡献在于策略优化而非 reasoning 建模;它借用了 CoT 的名义,但还远未构建出真正适应视觉领域的 reasoning 表达机制
但是 autoregressive 的图像生成符合 LLM 这种的 next token prediction 的范式,即在当前状态(已生成的 token 序列)下,选择下一个动作(token)的概率,呈现出序列决策或策略选择的特性。用 RL 进行优化是合理的,但其更应该类似于 LLM 中的 preference alignment(RLHF、DPO)
BiCoT-GRPO(Bi-level CoT-guided RL with Group-Relative Patch-wise Optimization)
核心优化框架:
利用强化学习而非传统 SFT
原因1:ULM(unified LMMs,e.g. Show-o)本身已具备基本能力,RL 可以更灵活地引导模型自主学习推理
原因2:RL 特别适合优化推理流程(而不仅仅是输出结果)
优化流程:
- 生成语义级 CoT(prompt 解析与图像规划)
- 将其作为条件,指导 token 级 CoT 生成
- 对同一 prompt 生成多个图像
- 用 group-relative reward 评估一组生成质量,统一反向传播优化两级 CoT
奖励设计:不使用单一标准,而是使用多个视觉专家模型构成奖励集合(如BLIP、DINO等)
避免 reward hacking,提高奖励稳定性与多样性;同时提升图像与 prompt 的一致性、视觉质量与语义合理性
2 Method
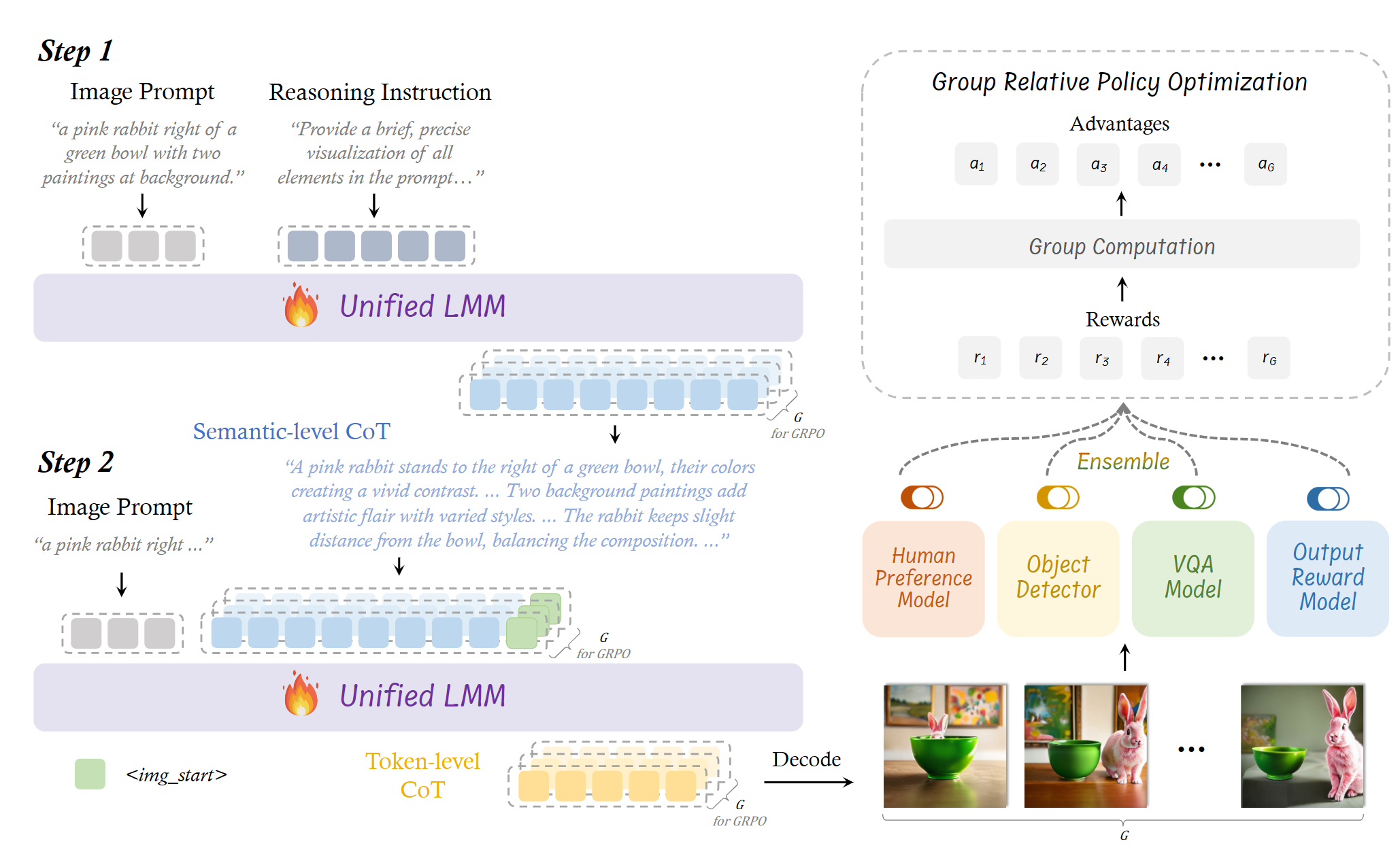
2.1 双层 CoT
Semantic-level CoT:在生成图像之前,先进行文本层面的推理和规划,例如理解提示词中的深层意图、推断场景中应有的物体及其关系、排列和动作等。像画家在动笔前构思整体场景。
- 增强跨模态理解能力,使得生成更加符合用户真实意图
比如: Prompt: "A flower cultivated in the country where Amsterdam is located." Semantic CoT 推理出应为*“tulip”*,而不是盲目生成花(阿姆斯特丹 → 郁金香)
Token-level CoT:在图像生成的过程中逐步生成 patch/image tokens,每个 patch 的生成依赖于前面的内容。像画家一点点绘制图像,保持局部细节和整体一致性。
- 增强图像局部一致性和视觉连贯性
Token-level CoT 详细机制:
1️⃣ 输入阶段:生成 Token-level CoT 的输入是
- image prompt
- 上一步生成的 Semantic-level CoT
- 特殊 token
<img_start>:用于告诉 ULM 开始生成图像 token
2️⃣ 生成阶段:ULM 会 step-by-step 地生成图像 token
- 每个 token 的生成依赖于前面的 token
- 这就形成了一个 token-level 的推理链(visual CoT),本质上是局部细节的递进建构过程
- 所有 token 生成完后,组成一个 grid(图像的 latent 表示),被送入 image decoder 解码成最终图像
3️⃣ 评估阶段:
- 对于每个 image prompt,会生成 N 个图像(N 组 token-level CoT)
- 每个图像会被送入多个 vision experts(HPM、Detector、VQA、ORM)
- 得到每个图像的 reward 分数
- 再通过 GRPO:
- 比较该图像的 reward 相对于同组(同 prompt)的其他图像
- 用于更新模型参数,让模型偏好那些 token-level CoT 更高质量的图像路径
这个 Token-level CoT 其实还是相当于是生成图片进行优化,甚至还不如上一篇 Can We Generate Images with CoT 有推理的感觉,他这里的 CoT 就是指的连续的 image tokens 呗(没有思维的感觉)
- 不是显式的 reasoning chain(比如“为了生成这只猫,我先想它在沙发上、然后想颜色……”这种 step-by-step 思考)
- 也没有中间 token 做显式 planning、修改或校准
- 只是将自然存在的 token-by-token decoding 当作“CoT”,在训练阶段通过 reward 选择“好”的 tokens
2.2 BiCoT-GRPO
GRPO(Group Relative Policy Optimization)是 DeepSeek 提出的一种 RL 策略优化框架。它通过成组地评估生成样本质量的相对表现
🧩 BiCoT-GRPO结构:
- 语义级CoT生成阶段:
- 输入 Image Prompt 和设定的 prompt(Reasoning Instruction)
- 输出语义推理文本(semantic-level CoT)
- 图像生成阶段:
- 输入 Image Prompt + 语义级 CoT +
<img_start>标记 - 通过 token-level CoT 逐步生成图像 tokens,再由解码器转换成图像
- 输入 Image Prompt + 语义级 CoT +
🔁 奖励机制:
- 为了稳定奖励信号,设计了视觉专家集成打分器(Ensemble of Vision Experts),包括多个图像理解模型(例如CLIP、Inception等)共同对生成图像打分
- 生成多个图像(N个)后比较它们的相对质量,使用组内相对得分而非绝对打分
2.3 Ensemble of Generation Rewards
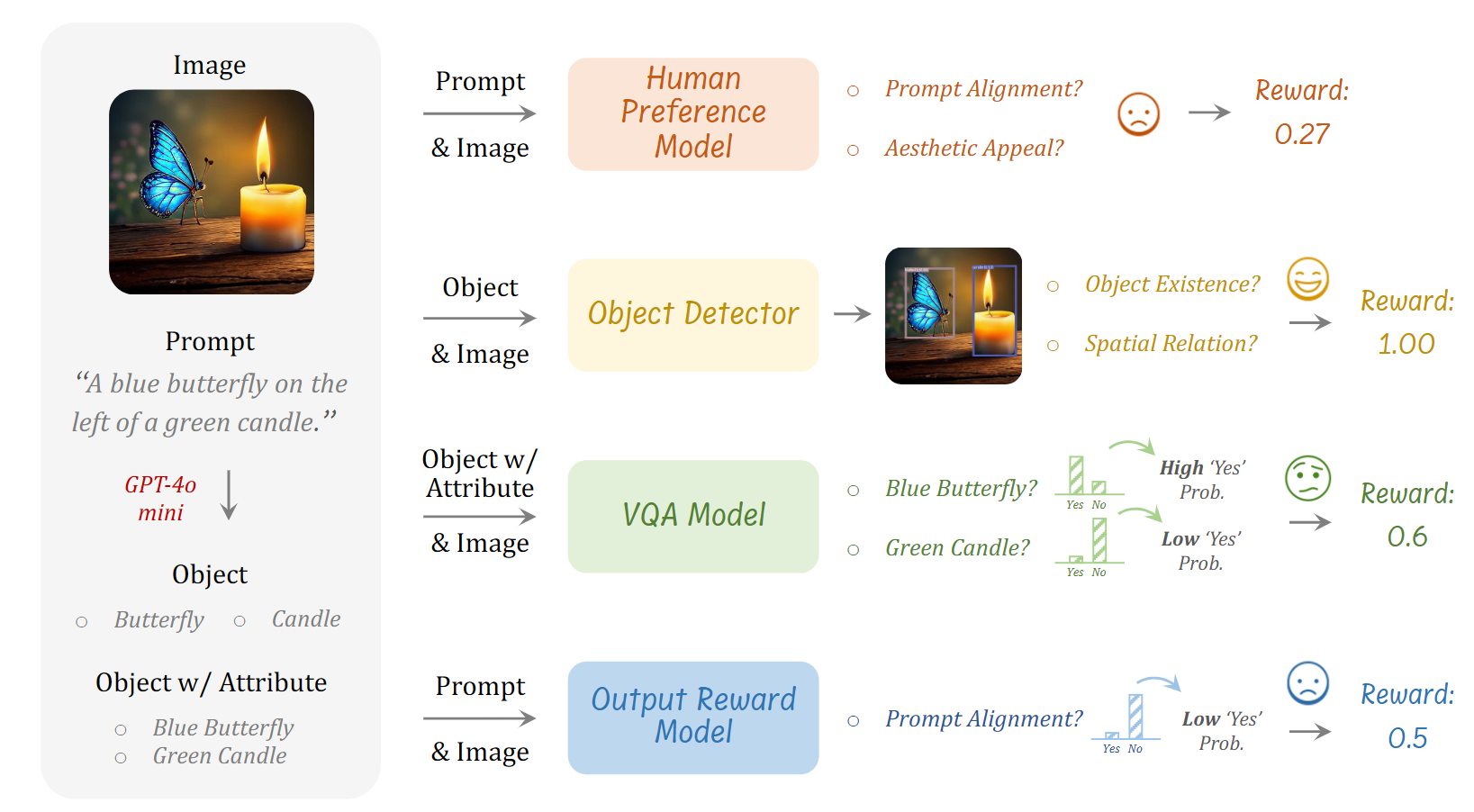
为了评估生成图像的质量,BiCoT-GRPO 不使用固定规则,而是设计了一个 多专家融合的奖励机制(ensemble of reward models),从多个视角对图像进行评分,确保奖励的全面性与鲁棒性,避免模型专注于“破解”某个单一奖励函数
四类 vision experts:
Human Preference Model (HPM):衡量图像的审美和对提示语的契合度
- 使用 HPS 或 ImageReward
- 机制:模型基于大量人类标注的图像排名学习,输出人类偏好评分
Object Detector:判断图像中目标的存在性、数量、空间关系。
- GroundingDINO, YOLO-World
- 机制:检测提示语中所有对象 是否出现在图像中;计算:
- 存在性得分(是否检测到该对象);
- 空间得分(如位置是否正确,使用 IoU 与相对方向);
- 数量得分(检测数量是否正确);
- 奖励函数 :
- if spatial relationship in the prompt → 0.6 × 空间得分 + 0.4 × 存在性得分
- if number in the prompt → 检测数量正确与否
- else → 平均存在性得分
Visual Question Answering (VQA) Model:判断目标是否存在,属性是否匹配。
BLIP、GIT、LLaVA
机制:将 image prompt 中的目标+属性转化为问句(如:"A red dog?"),让模型回答是否存在:
Output Reward Model (ORM):判断图像与提示整体是否对齐。
- OneVision 微调后的 LLaVA
- 机制:直接输入整个 image prompt,模型输出是否匹配的概率(与 VQA 类似,但输入是整个 image prompt)
融合:对每个专家的输出进行平均,得到最终的 reward 。