Vstar 学习笔记
1 Motivation
https://arxiv.org/abs/2312.14135
V* 感觉就类似于 agent
当前的多模态大模型(比如 LLaVA、GPT-4V 等)在处理复杂或高分辨率图像时,存在两个主要问题:
- 视觉信息获取不足:图像编码器(如 CLIP)通常对低分辨率图像训练,导致在高分图像中容易忽略细节。
- 缺乏主动搜索能力:模型不会像人一样“知道自己不知道”,也不会主动查找关键视觉信息。
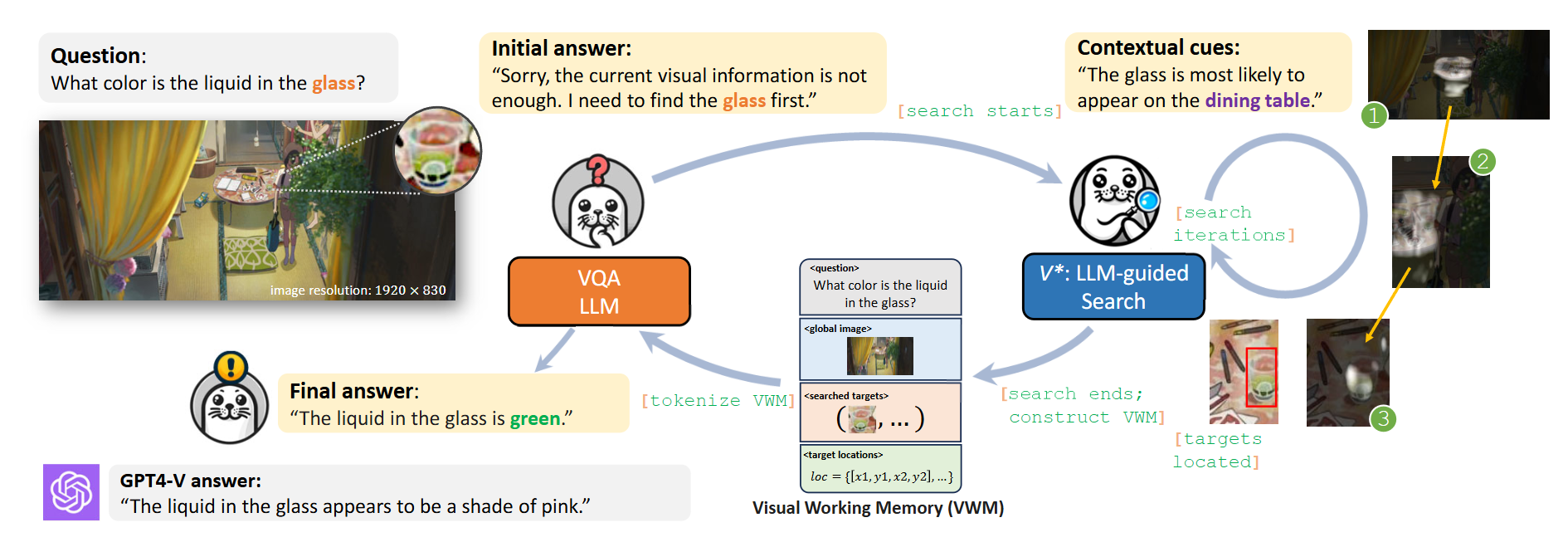
V*:引入了一个 LLM 驱动的视觉搜索模块 V*,模仿人类的视觉搜索方式
- Show:VQA LLM先尝试回答问题
- 如果能回答,就直接结束
- 如果回答不了,它就列出缺失的关键信息(如:需要找到“红色杯子”)
- Search(V*启动):如果无法回答,就启动 V*,根据上下文、常识和语言模型的推理来定位图像中的关键区域
- Tell:搜索到的所有信息收集到“视觉工作记忆(VWM)”,再次输入给LLM,从而更准确地回答问题。
2 Method
提出了一个新的 MLLM 框架,叫做 SEAL,全称是 Show, Search, and Tell。它的基本思路是模拟人类在看复杂图片时,会主动搜索关键细节、记在脑子里(视觉工作记忆 VWM),然后基于这些信息做更好的推理和回答。
2.1 SEAL
整个SEAL系统有两个核心部分:
- VQA LLM
- Visual Search Model
它们通过一个叫做 Visual Working Memory (VWM) 的结构来互相协作。
VWM就是一个不断收集、更新信息的小本子,里面记录了原图、问题、找到的目标小图、目标位置。
- 第一步,VQA LLM 先看图 I 和问题 T,尝试回答。
- 如果能回答,就直接结束;
- 如果回答不了,它就列出缺失的关键信息(比如:需要找到“红色杯子”、“猫的眼睛”这些小目标)。
- 第二步,初始化 VWM,把原图 I 和问题 T 加进去。
- 第三步,针对每一个缺失的目标:
- 用 Visual Search Model 去整个图片里搜目标(用一个优先队列 q 来管理搜索过程);
- 如果找到了,就把对应的小图裁剪出来,加到 VWM;
- 如果找不到,就在 VWM 中记录“没找到”。
- 最后,基于丰富了的 VWM 信息,VQA LLM 再重新生成最终回答。
2.2 数据构建
负样本数据(100k)
让模型学会识别:“我回答不了问题,因为图里没有这个目标”。模型要能明确地说出:“我需要 A 和 B 才能回答。”
图像中真的没有相关目标;或者目标太小(< 20x20像素),CLIP提不出来特征;
构造方式:
- 用 GPT-3.5 生成和目标物相关的问题;
- 用 COCO2017 图片;
VQA数据(167k)
让模型在已有目标的基础上回答问题。
- GQA 数据(70k):使用 GT 标注的目标物,作为 VWM 的目标输入;用 GPT-3.5 把简短回答扩展成完整句子。
- Object Attribute 数据(51k):用 VAW 数据集(关于物体颜色、材质等);把描述性信息变成问答格式,提取出相关物体作为目标。
- Spatial Relationship 数据(46k):在 COCO2017 上构造两个物体之间的空间关系问题(如“A在B的左边吗?”);这两个物体就是搜索目标。
LLaVA 指令微调数据(120k)
维持模型的通用指令能力:
- 使用 LLaVA-80K 中的图文指令数据(图片主要来自 COCO);
- 再额外挑选40k条:从问题中提取出能匹配COCO类别的目标,作为搜索对象。
2.3 V* 🌟
视觉搜索 Visual Search 跟指代理解(REC)很像:都是给一句文本描述,在图里找对应的目标。但视觉搜索要更灵活:
- 支持任意分辨率的大图(不仅仅是标准尺寸图片);
- 有时候需要在整张图中彻底搜索;
- 搜索效率很重要,要尽可能又快又准地找到目标。
2.3.1 Model Structure
总体设计理念:
- 模仿人类视觉搜索:先大致推测哪里可能有目标,再细看细找;
- 不是死遍历(暴力patchify);
- 引入一个多模态大模型(MLLM) + 局部定位模块。
组件:
- MLLM(多模态语言模型):
- 输入图片和搜索指令:“Please locate the [object] in the image.”
- 输出一个特殊token
<LOC>,包含位置相关的上下文特征; - 基于
<LOC>嵌入,拿到两个向量:- vtl → 给目标定位
- vcl → 给搜索提示
- Image Encoder + 两个Decoder:
- Dtl(Target Localization Decoder):类似两个MLP head,预测坐标和置信度。
- Dcl(Search Cue Localization Decoder):类似 SAM 的掩码分割头,输出热力图,指示可能的目标区域。
3.3.2 Search Algorithm🌟
V* 搜索过程大致是:
直接定位:
- 用“Please locate [object]”指令
- 如果目标坐标置信度高 → 成功找到
检查热力图:
- 如果目标置信度低,看 Search Cue 热力图
- 如果热力图中有显著区域(最大值超过阈值 δ)→ 用来引导下一步搜索
使用上下文推断(contextual cue):如果热力图也不明显
- 询问 MLLM:“目标最可能出现在图中的哪个区域?”
- 再基于上下文区域生成新的 Search Cue Heatmap
递归图像分割搜索:
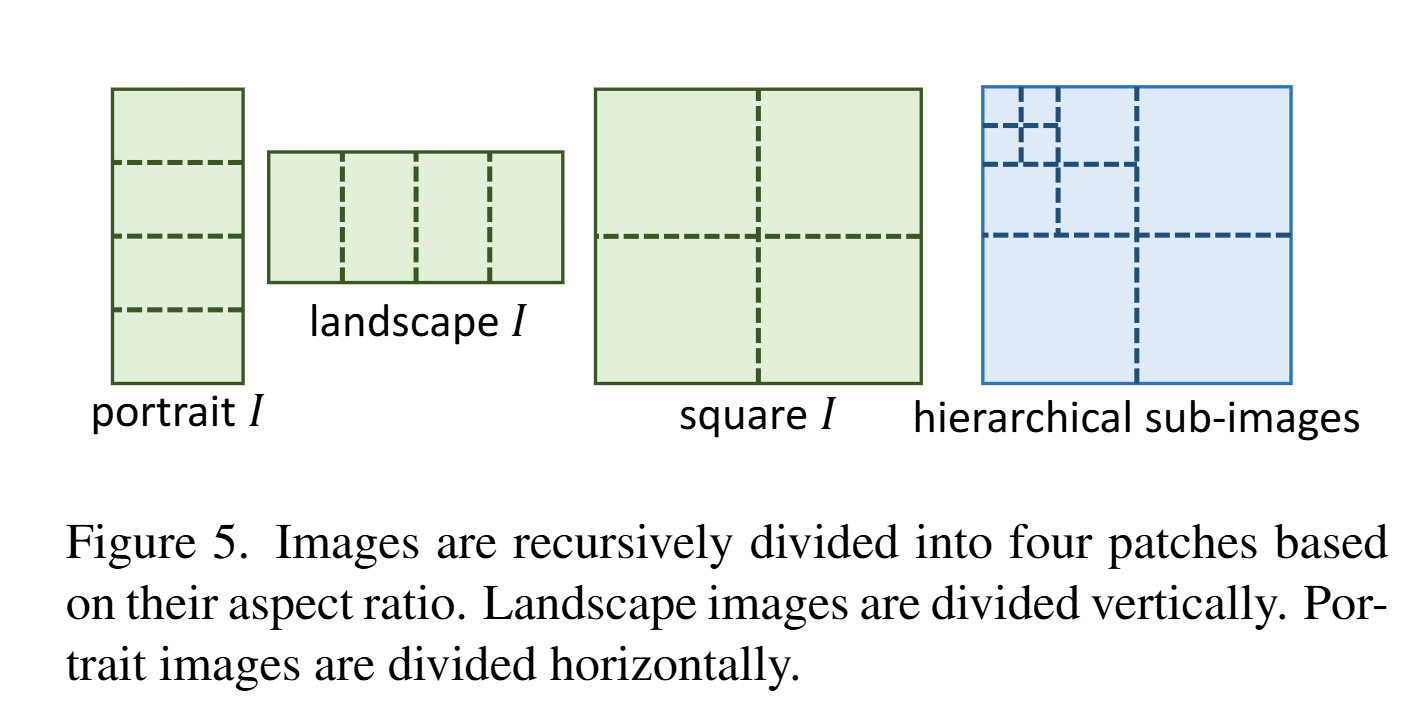
- 把图像递归地按四块划分(根据图像长宽比例调整,保持patch接近正方形);
- 基于热力图的优先级,按分数高的子图优先搜索;
- 直到找到目标或patch小到不能再切
搜索过程 example:一行代表一个过程,右边就是热力图和最后的 bbox

2.4 Model Training
主要包括两个模型:
- VQA 模型(用于理解问题、定位目标)
- 视觉搜索模型(用于生成热图和具体定位)
2.4.1 VQA 模型训练
使用基础模型:Vicuna-7B-1.3
训练分两阶段:
- 特征对齐阶段:冻结 vision encoder 和 LLM,仅训练两个投影模块(linear projection / resampler),图像-文本对用的是 LLaVA 用的 558K LAIONCC-SBU 子集。
- 指令微调阶段:冻结 vision encoder,训练 Vicuna 和 projection 模块,使用构建的 387K 任务数据
推理输入格式(最终喂给 LLM):
<Image>
Additional visual information:
{Object name 1} <Object> at [x1, y1, x2, y2];
{Object name 2} <Object> at [x1, y1, x2, y2];
...
Question<Image>和<Object>都是通过 projection 得到的图像/目标的 token。- 若只有一个目标,就用 linear proj;否则用 resampler 来多目标聚合。
2.4.2 视觉搜索模型训练
模型结构:
- MLLM:LLaVA-7B-v1.1
- Vision encoder:OWL-ViT-B-16
- 包含两个模块:
- Dcl:Dense cue localization module → 输出热图
- 用 BCE loss + Dice loss 训练
- Dtl:Discrete target localization module → 输出具体目标 box
- 类似 DETR,用 set prediction loss + focal loss
- Dcl:Dense cue localization module → 输出热图
训练设置:
- 总步数 100K,batch size 64,lr=1e-4
- 数据采样比例:General detection/segmentation:Referring:VQA = 15:8:15
- 参数冻结与可训练策略:
- 冻结:image encoder(视觉骨干)、Dtl 中的坐标 MLP
- 可训练:MLLM(用 LoRA)、word embedding、Dcl、score MLP