LR 语法分析 实验实现
源码可以看Github上的仓库
1 原理
1.1 主要原理
基于 Bison 和 Flex 的 LR 语法分析生成 AST(Abstract Syntax Tree):
Flex词法分析:
lrlex.l- Flex用于生成词法分析器。词法分析器负责将源代码分割成一个个称为词法单元(tokens)的基本语法单元。
- 在Flex文件中,定义正则表达式规则,每个规则与一个动作关联。当输入的源代码匹配规则时,相应的动作会被执行。动作通常包括设置
yylval中的值,用于传递给语法分析器。
Bison语法分析:
lrparser.y- Bison用于生成语法分析器。语法分析器负责将词法单元序列转换成语法树。
- 在Bison文件中,定义文法规则,每个规则包含产生式和相应的动作。产生式规定了语法结构的形成,而动作通常包括创建抽象语法树节点、执行语义动作等。
- Bison使用LR(Left-to-Right)语法分析。
抽象语法树的构建:
ast.h和ast.c在Yacc的文法规则中,会定义如何构建抽象语法树。每个文法规则的动作部分都会调用创建节点的函数,这些节点最终组成了整个抽象语法树。
在之前的递归下降语法分析中,我们需要自己写的
rd_函数 来编织这些节点在一起,而在这个实验中,我们是通过.y文件中的 Grammar Rules 中的每个产生式相关的语义动作来编织
主函数:
main.c- 函数入口,直接执行
yyparser()开始对输入串进行分析 - 语法分析器
yyparser()需要下一个新单词时,会调用词法分析子程序yylex(),yylex()从输入串中识别一个单词后返回。
- 函数入口,直接执行
1.2 Bison 文件
Bison文件(通常以 .y 为扩展名)包含了语法规则、终结符、非终结符以及与语法动作相关的代码。下面是一个简化的Bison文件的典型结构:
%{
// C Code Section
#include <stdio.h>
#include "node_type.h"
extern int yylex(); // 词法分析器函数的声明
%}
// Declarations Section 声明部分
%token <iValue> NUMBER
%type <pAst> program expr factor term
// Union Declaration 定义了yylval的类型
%union {
int ivalue;
past node;
}
// Grammar Rules 语法规则
%%
...
statement: expr { /* 语义动作代码 */ }
| ID '=' expr { /* 语义动作代码 */ }
| PRINT expr { /* 语义动作代码 */ };
...
%%
// C Code and Functions Section
void yyerror(const char *s) {
fprintf(stderr, "Parser error: %s\n", s);
}
int main() {
yyparse(); // 分析的入口点
return 0;
}上述代码是一个简单的Bison文件结构的示例,其中包含了一些常见的部分:
C Code Section (
%{ ... %}):这个部分包含在生成的C文件中直接插入的C代码。在这里,可以包含头文件、声明全局变量、定义辅助函数等。一般是整体性的声明和定义Declarations Section:在这个部分,你声明终结符、非终结符、运算符的结合性和优先级等信息。
%token和%type:声明了不同的终结符和非终结符,同时指定了它们的语义值类型,如%token <int_value>: 定义了num_INT、Y_INT、Y_VOID、Y_CONST等终结符的语义值类型为int_value。%token <float_value>: 定义了num_FLOAT终结符的语义值类型为float_value。%token <id_name>: 定义了Y_ID终结符的语义值类型为id_name。%type <pAst>: 定义了非终结符program、Exp、AddExp等的语义值类型为pAst。
终结符在生成的 xxx.table.h 中自动形成
enum yytokentype以Y_为前缀的大写字母标识符,在 Flex 词法分析的时候要用Union Declaration (
%union { ... }):这里声明了一个 union,用于在语法规则中传递值,即定义了 yylval 的类型生成的 xxx.table.h 会包含其定义与声明
Grammar Rules (
%% ... %%):在 %% 之间的部分定义了文法规则,包括产生式、终结符、非终结符以及与每个产生式相关的语义动作。在规则中,你可以使用C代码执行语义动作,构建抽象语法树节点。具体的构造AST的函数就需要自己编写了,一般在
ast.h和ast.c中C Code and Functions Section:这个部分包含在生成的C文件中直接插入的C代码,通常包括错误处理函数(
yyerror)和程序的入口点(main)等。也可以将这部分单独放到另一个 main.c 文件里去,gcc 编译的时候一起编译就行
2 实验过程
2.1 学习LR语法分析
2.1.1 例子理解
Lex 部分:
%{ #include <stdio.h> int yylex(void); void yyerror(char *); %} %token NUMBER- 在
%{ ... %}部分,你可以放一些 C 代码,这部分代码会直接复制到生成的lex.yy.c文件中。 %token NUMBER表示NUMBER是一个词法单元类型。
- 在
Yacc 部分:
%% program: program expr '\n' { printf("%d\n", $2); } | ; expr: NUMBER { $$ = $1; } | expr '+' NUMBER { $$ = $1 + $3; } | expr '-' NUMBER { $$ = $1 - $3; } ; %%- 在
%%之间是文法规则的定义。这里定义了两个非终结符program和expr,以及一个终结符NUMBER。 program规则表示一个程序由一个或多个表达式组成,每个表达式之间用换行符分隔。在每个程序结束时,输出表达式的值。expr规则定义了表达式的形式,可以是一个数字(NUMBER),也可以是一个表达式加上或减去一个数字。
- 在
错误处理:
void yyerror(char *s) { fprintf(stderr, "%s\n", s); }yyerror函数用于处理语法错误。在这里,它简单地将错误信息输出到标准错误流。
主函数:
int main(void) { yyparse(); return 0; }main函数调用yyparse(),这个函数由 Yacc 生成,负责解析输入。
这个程序的作用是简单的四则运算,输入表达式,程序将计算并输出结果。
2.1.2 例子调试
使用Bison工具解析calc3.y文件,生成对应的解析器文件
y.tab.c和语法分析头文件y.tab.h。-d选项告诉Bison生成头文件。bison -d calc3.y使用Flex工具解析calc3.l文件,生成词法分析器文件
lex.yy.c。Flex会读取calc3.l中的规则,并生成一个根据这些规则匹配输入文本的词法分析器。flex calc3.l使用GCC编译器将生成的文件进行编译链接,生成可执行文件
calc。calc3.tab.c包含了由Bison生成的语法分析器的实现。lex.yy.c包含了由Flex生成的词法分析器的实现。ast.c是你的抽象语法树的实现文件。main.c是你的主程序文件。
gcc -o calc calc3.tab.c lex.yy.c ast.c main.c运行calc:
执行生成的
calc可执行文件。./calc输入待解析语句
2+3*4/5-3,得到解析结果: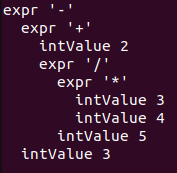
2.2 编写LR分析程序
2.2.1 Bison文件
Bison文件 —— lrparser.y
声明部分
%{ ... %}:- 包含了标准输入输出头文件
stdio.h和抽象语法树的头文件ast.h - 并声明了词法分析 函数
yylex和错误处理函数yyerror,还引入了一个外部变量type。
%{ #include <stdio.h> #include "ast.h" int yylex(void); void yyerror(char *s); extern int type; %}- 包含了标准输入输出头文件
声明Union
%union:- 这个部分定义了一个联合体,用于在语法分析时传递不同类型的值。在你的语法规则中,你使用了
%token和%type来声明终结符和非终结符的类型。这些类型将被放入这个联合体。
%union{ int token; int int_value; float float_value; char* id_name; past pAst; };- 这个部分定义了一个联合体,用于在语法分析时传递不同类型的值。在你的语法规则中,你使用了
声明终结符和非终结符:
- 在这个部分声明了终结符和非终结符。每个终结符都有一个相关的类型,这些类型被放入上面定义的联合体中。
%token <int_value> num_INT Y_INT Y_VOID Y_CONST Y_IF Y_ELSE Y_WHILE Y_BREAK Y_CONTINUE Y_FLOAT Y_RETURN %token <int_value> Y_ADD Y_COMMA Y_DIV Y_LPAR Y_SUB Y_LSQUARE Y_MODULO Y_MUL Y_NOT Y_RPAR Y_RSQUARE Y_RBRACKET %token <int_value> Y_LESS Y_LESSEQ Y_GREAT Y_GREATEQ Y_NOTEQ Y_EQ Y_AND Y_OR Y_ASSIGN Y_LBRACKET Y_SEMICOLON %token <float_value> num_FLOAT %token <id_name> Y_ID %token YYEOF %type <pAst> program Exp AddExp MulExp UnaryExp CallParams PrimaryExp LVal ArraySubscripts %type <pAst> Block BlockItem BlockItems Stmt Stmt1 RelExp EqExp LAndExp LOrExp %type <pAst> FuncDef FuncParam FuncParams Type %type <pAst> CompUnit Decl ConstDecl ConstDefs ConstDef ConstExps ConstInitVal ConstInitVals %type <pAst> VarDecl VarDecls VarDef InitVal InitVals ConstExp语法规则部分
%%:在这个部分定义了语法规则。每个规则由产生式组成,产生式之间用竖线
|分隔。在产生式中,使用了终结符和非终结符,以及语义动作(C代码块),用于构造抽象语法树。这里列举3个例子解释:如下,表示
program是由CompUnit和YYEOF构成,其中由于 program 是程序的最顶层,所以直接showAst($1,0)来展示最终结果抽象语法树。program: CompUnit YYEOF{showAst($1,0);}如下,语法规则定义了
ConstInitVal非终结符。这个非终结符表示常量的初始化值,可以是单个常量表达式,也可以是一个由方括号括起来的常量初始化列表。ConstInitVal: ConstExp | Y_LBRACKET Y_RBRACKET {$$ = NULL; } | Y_LBRACKET ConstInitVal Y_RBRACKET {$$ = $2;} | Y_LBRACKET ConstInitVal ConstInitVals Y_RBRACKET {$$ = newInitList($2,$3); } ;具体来说,这部分的语法规则包括四个产生式:
ConstExp: 表示常量的初始化值是一个常量表达式。Y_LBRACKET Y_RBRACKET: 表示常量的初始化值是一个空的常量初始化列表,即一个空数组。Y_LBRACKET ConstInitVal Y_RBRACKET: 表示常量的初始化值是一个包含单个元素的常量初始化列表,其中元素为ConstInitVal的值。Y_LBRACKET ConstInitVal ConstInitVals Y_RBRACKET: 表示常量的初始化值是一个包含多个元素的常量初始化列表,其中第一个元素为ConstInitVal的值,后续元素为ConstInitVals的值。
在语法分析的过程中,当匹配到这样的结构时,对应的语义动作会被执行。例如,
$$ = $2;表示将ConstInitVal的值传递给ConstInitVals的值。这样,整个ConstInitVals就可以表示为一个包含多个元素的常量初始化列表的结构。如下,这部分的语法规则定义了
FuncDef非终结符,表示函数定义。这个非终结符包括两个产生式:FuncDef: Type Y_ID Y_LPAR Y_RPAR Block {$$ = newFuncDecl(get_stype($1->ivalue), $1->ivalue,$2, NULL, newCompoundStmt(NULL, $5));} | Type Y_ID Y_LPAR FuncParams Y_RPAR Block {$$ = newFuncDecl(get_stype($1->ivalue), $1->ivalue, $2, $4, newCompoundStmt(NULL, $6));} ;Type Y_ID Y_LPAR Y_RPAR Block: 表示函数定义中没有参数的情况。在语义动作中,调用了newFuncDecl函数来创建一个函数声明节点,其中参数get_stype($1->ivalue)表示获取函数返回类型,$1->ivalue表示获取类型的值,$2表示获取函数名,NULL表示没有参数,newCompoundStmt(NULL, $5)表示函数体。Type Y_ID Y_LPAR FuncParams Y_RPAR Block: 表示函数定义中包含参数的情况。在语义动作中,同样调用了newFuncDecl函数,不同之处在于参数部分,其中$4表示获取参数列表,newCompoundStmt(NULL, $6)表示函数体。
错误处理函数
yyerror:- 这个函数在语法错误发生时被调用,用于输出错误信息。
void yyerror(char *s) { printf("%s", s); }主函数
main:- 这是程序的入口点,调用
yyparse开始语法分析。
int main() { yyparse(); return 0; }- 这是程序的入口点,调用
2.2.2 AST构造文件
AST构造文件 —— ast.h 和 ast.c
ast.h:
用于定义抽象语法树节点类型和相关函数的头文件。以下是一些主要的内容和功能:
enum _node_type: 枚举类型,定义了许多节点类型的常量,例如STRUCT_DECL,VAR_DECL等。- 结构体
_ast:表示抽象语法树的节点结构。包含了节点的各种信息,例如类型、值、操作符等。 node_type:定义了enum _node_type的别名,使其更容易使用。type:全局变量,用于表示当前节点的类型。- 函数声明:定义了一系列用于创建和展示抽象语法树节点的函数,例如
newAstNode、showAst、newDeclStmt等。 - 头文件保护:使用了
#ifndef和#define,确保头文件在同一文件中被包含多次时不会导致重复定义。
这个头文件为抽象语法树节点的创建和展示提供了必要的结构和函数。它还定义了一些枚举类型和全局变量,以支持在语法分析和语义分析中跟踪节点类型。
ast.c:
其中包含了用于创建和显示抽象语法树(AST)节点的函数。以下是一些主要功能:
newAstNode: 创建一个新的AST节点,并对其进行初始化。showAst: 递归地显示AST的结构和信息,包括节点类型、值等。showTranstion: 显示整个翻译单元的AST。showCallExp,showCompoundStmt,showParaDecl: 显示函数调用、复合语句、函数参数的AST。get_id,get_stype,get_conststype: 辅助函数,用于获取标识符、变量类型和常量类型的字符串表示。- 一系列
new*函数: 用于创建不同类型的AST节点,例如声明语句、变量声明、函数声明、复合语句等。
这些函数的实现主要是通过调用
newAstNode创建新的节点,然后根据节点类型和属性进行设置。showAst函数用于以可读的方式输出AST的结构。