NeRF学习 —— 复现训练中的问题记录
训练问题
训练从尝试一开始,记录了一步一步修改改进,到尝试三就基本完成复现!
1 尝试一
训练中:在 Dateset 的 __getitem__ 函数中进行 shuffle,导致每次迭代都会 shuffle 整个数据一次,耗费大量时间
在经过10000次迭代(20个epoch)后:
psnr 整体是呈现一个上升的趋势,在10000次迭代后在24左右
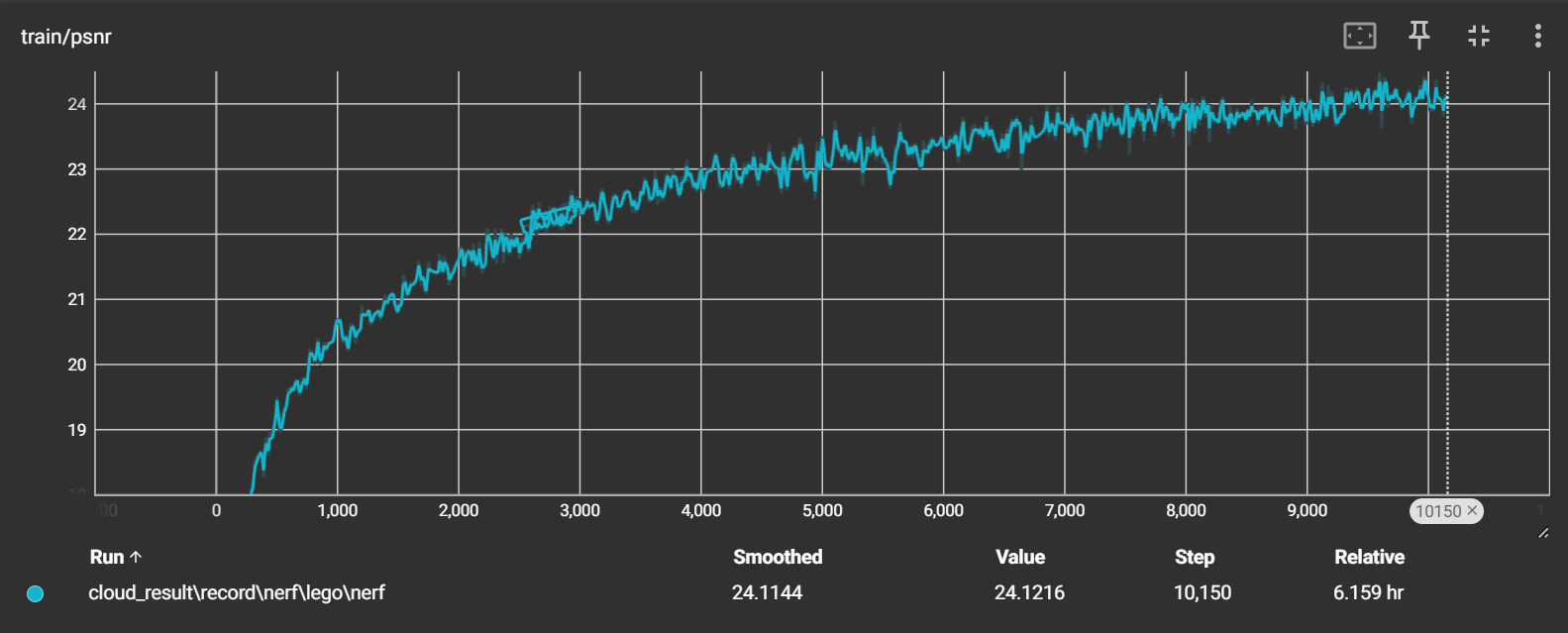
loss 从一开始整体下降,之后就一直在0.1225左右徘徊(感觉出现问题)没有明显的下降趋势
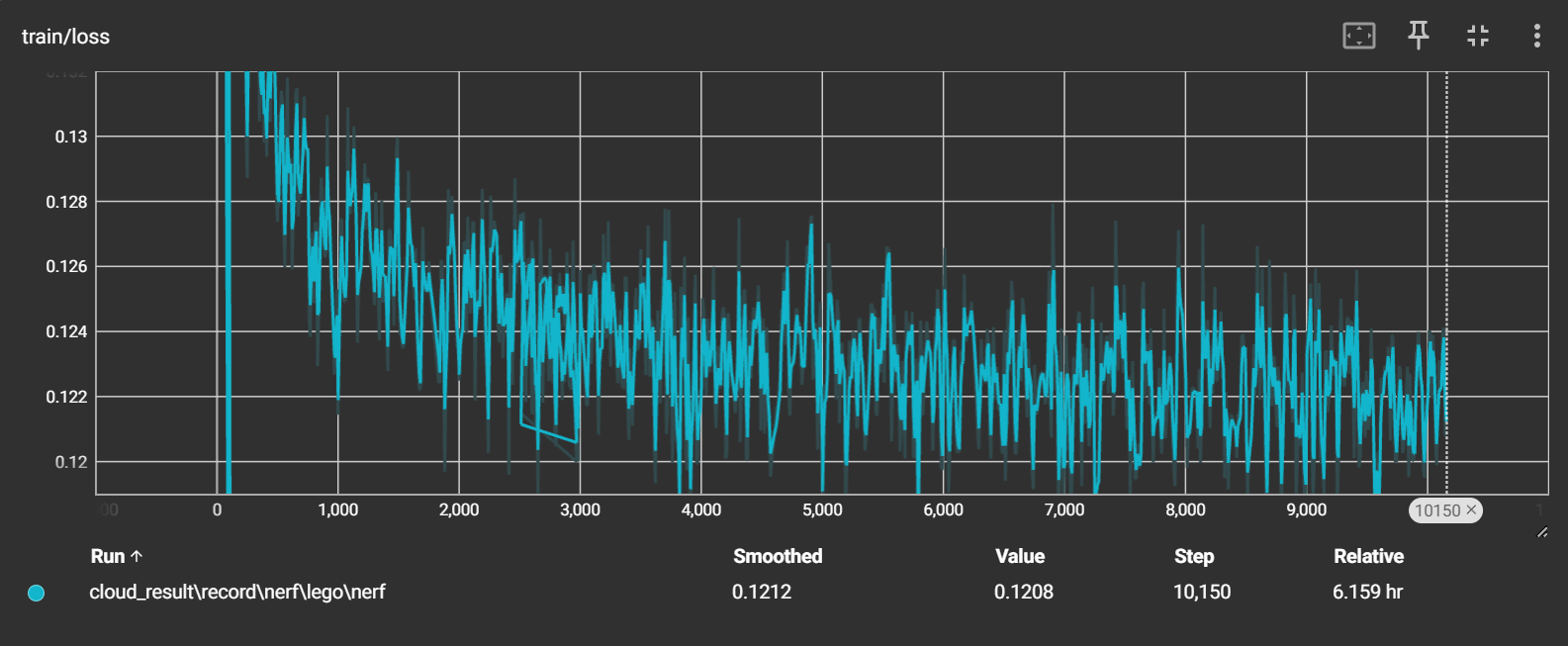
分别在5000次和10000次迭代的时候 evaluate 了两次:
- 第一次:loss = 0.1201,psnr = 22.94,mse = 0.005223
- 第二次:loss = 0.1191,psnr = 23.8,mse = 0.004276
推理得到的图像如下:

其实在训练时获取光线时本来就是打乱了的,传入
__getitem__的index就是随机的,但是发现在移除所有光线的 shuffle 后,训练出现问题(一直psnr = inf,loss = 0),具体原因还未知、
2 尝试二
现在我将 shuffle 放到了 __init__ 中去,只在创建数据集时进行一次 shuffle,训练正常进行,时间相比以前有了提升!
但出过拟合问题!
在2500次迭代(5个epoch)后:
loss 持续下降到 0.000292,停止后再次开始训练时断崖上升
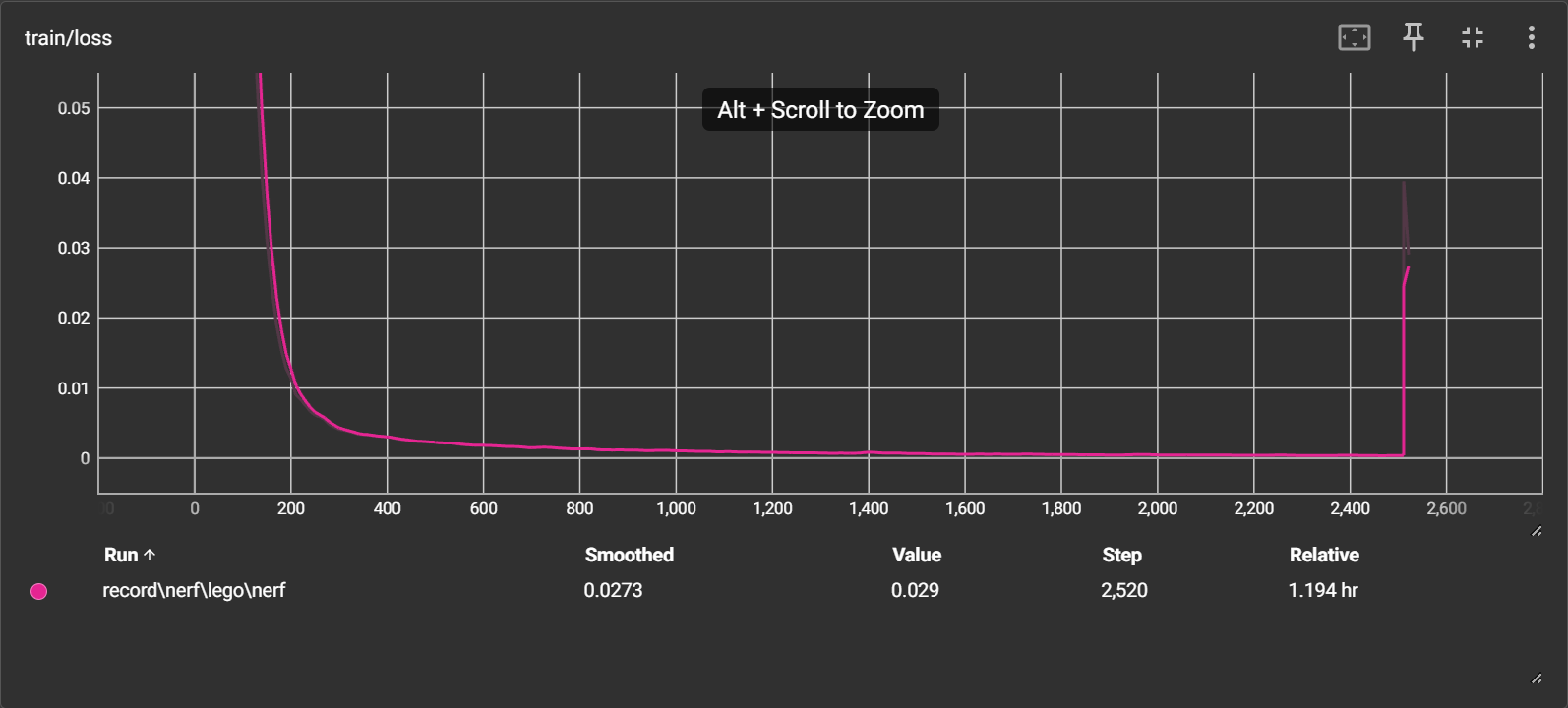
psnr 持续上升到40,停止后再次开始训练时断崖下降
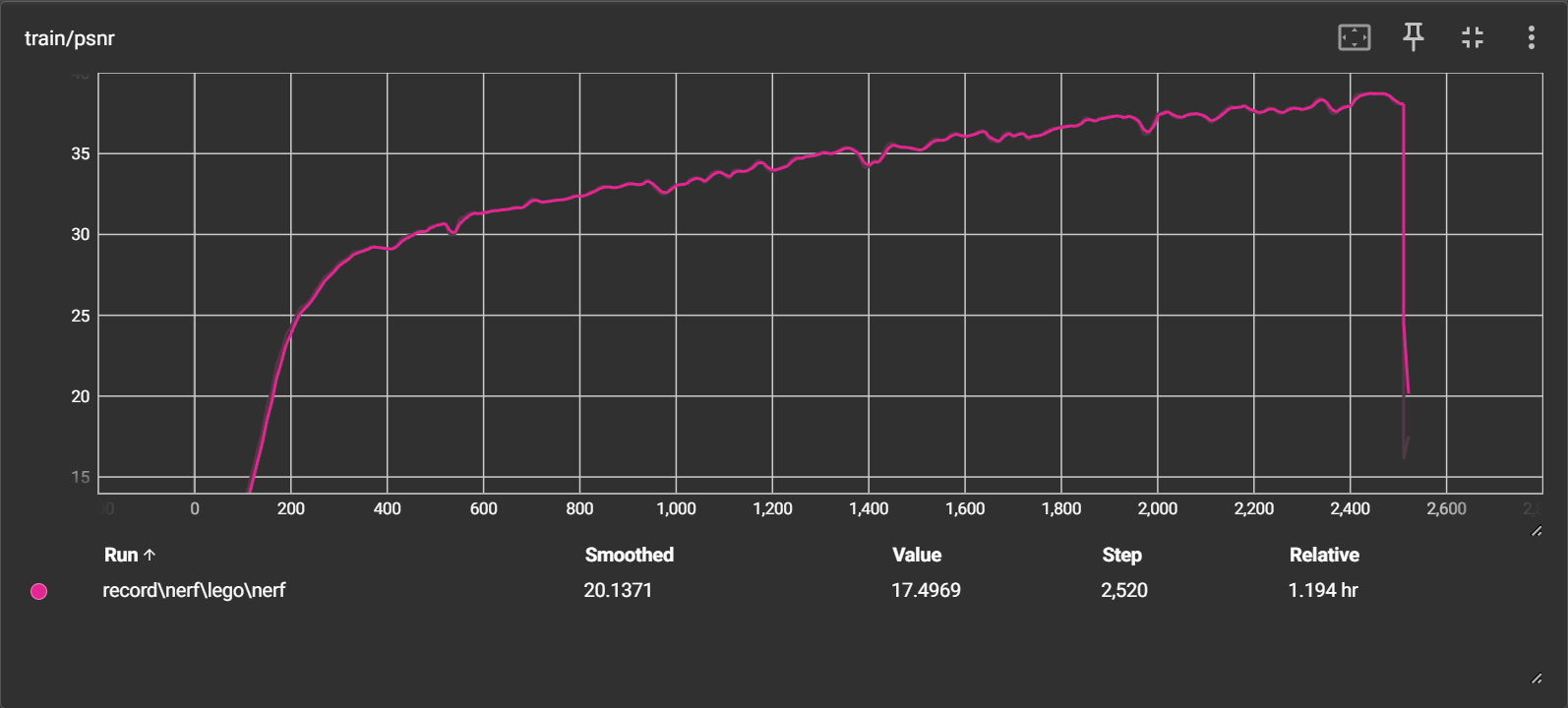
使用 run.py 的 evaluate 模块进行测试:
输出的图像与指标不符,loss = 0.055,psnr = 15.4939,mse = 0.0282;具体生成图像也是比较糟糕,只能看到大致雏形

问题:
发现了问题出现在数据集的 __getitem__ 上,每次传入的 index 是随机图片索引,只有只有 1~200,只能得到前面的 1~200*1024 的数据太狭隘了,导致了过拟合。
目前解决方案在 index 的基础上乘上图像的宽高:
index = index * self.H * self.W3 尝试三
经过上述的修改,并且参考 nerf-pytorch 的代码在每隔一段时间(我现在暂时设定self.N_rays * cfg.ep_iter 次,即 1024*500)就会重新打乱一遍所有的32000000条光线
我将代码放到了阿里云的服务器上进行训练,经过10.48小时的训练,总共迭代了71,000次(142个epoch)
训练:
loss 持续下降,目前在0.003左右波动
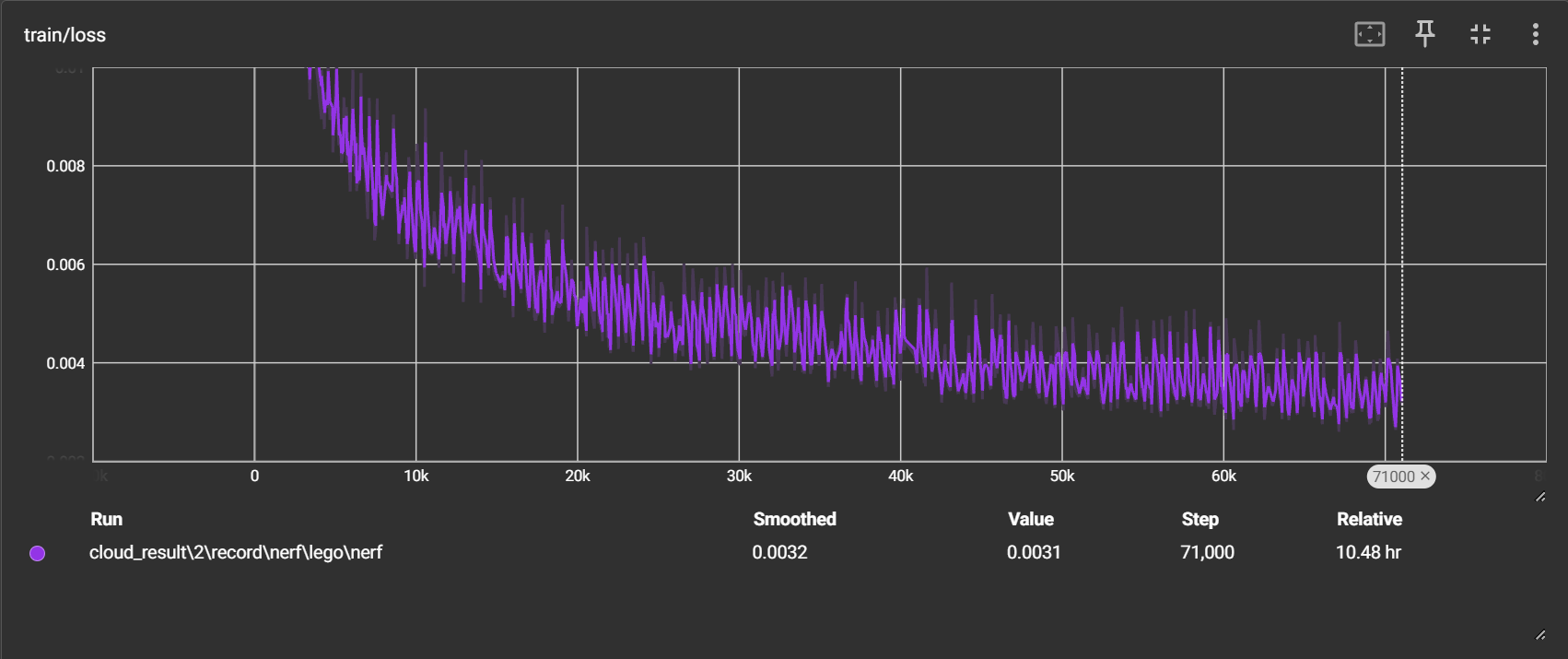
psnr 持续上升,目前在32左右波动
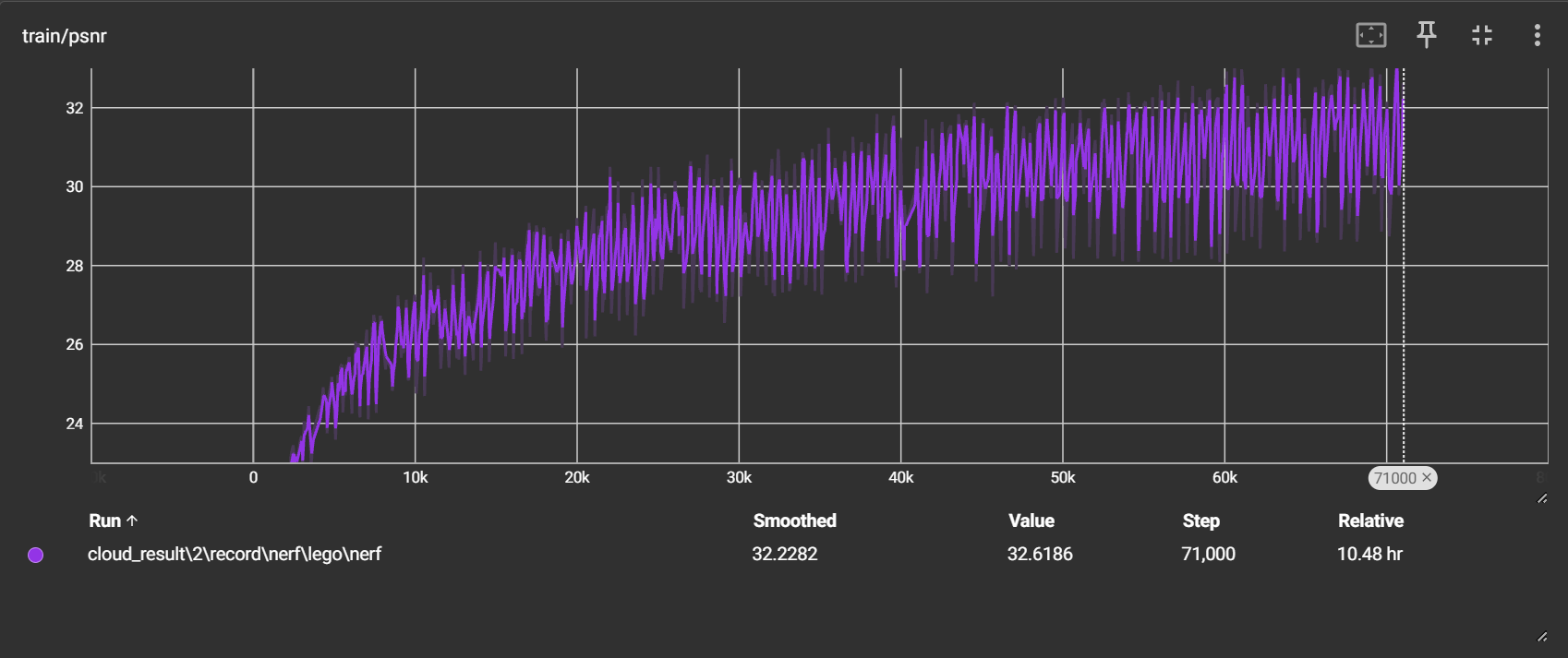
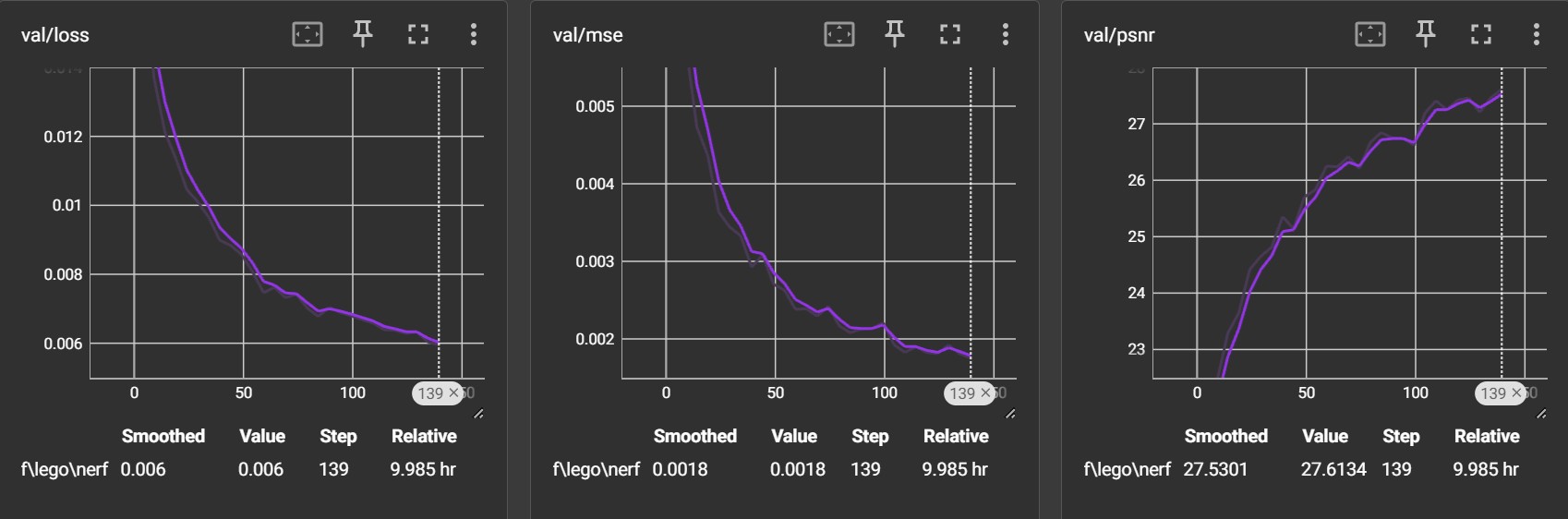
evaluate:我设定了每隔2500次迭代(5个epoch)就进行一次 evaluate,每次为了节省时间只用10张图片进行测试
loss 持续下降到0.006,mse 持续下降到0.0018,psnr 持续上升到27.6134
得到的图片:

训练完后对整体(200张图片)进行了一次 evaluate:得到 psnr = 28.4860
与尝试一进行对比:在10000次迭代左右,时间大大减少,且loss、psnr都更加优秀
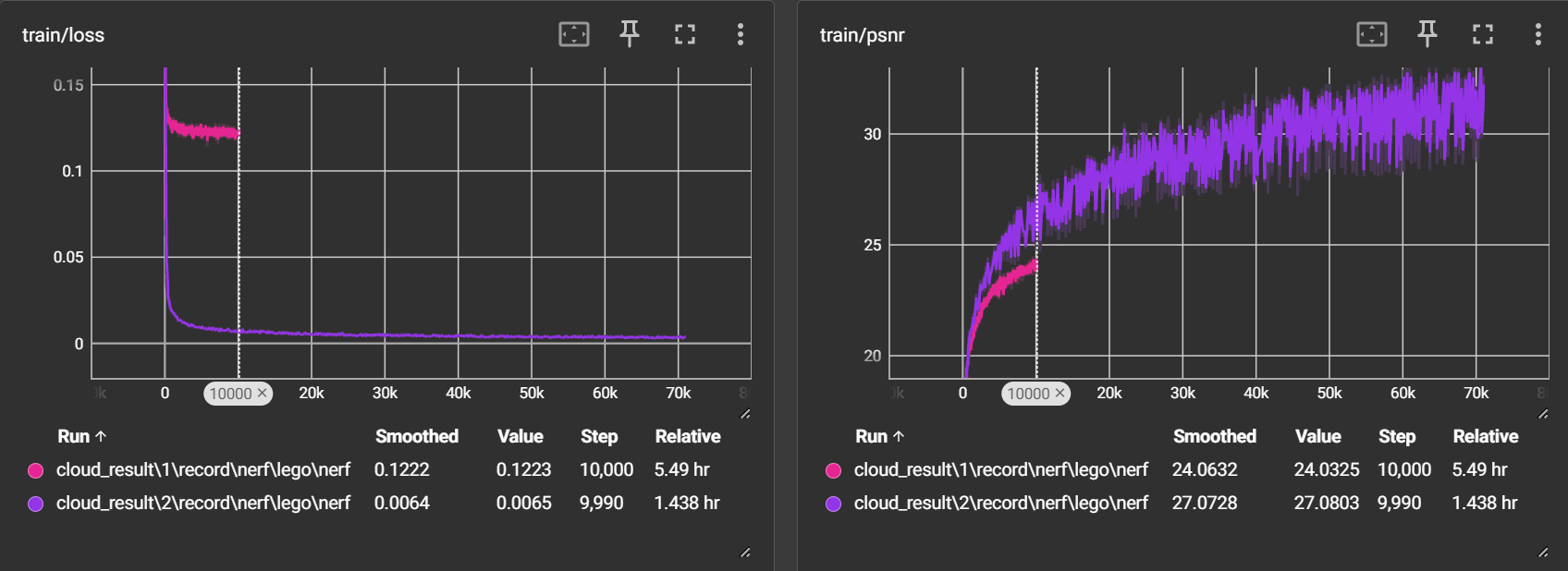
4 问题
4.1 psnr 不上升
有时开始训练时的psnr从9左右开始就会导致 psnr 不上升一直徘徊在9左右,loss 正常下降,重新开始训练就有可能回归正常!
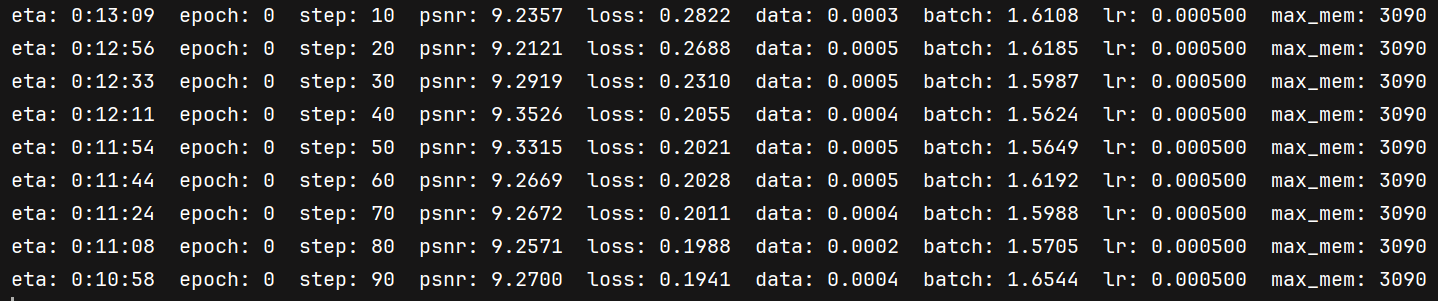
尝试了5000次的迭代(10个epoch),测试出来图片如下:

目前原因可能是初始化导致的😭(小问题,重新开始训练就行)
4.2 加载再训练
当我将保存的模型加载接着训练的时候,我发现了 loss 相较于之前突然变大了再缓慢下降,psnr 也是相似的,一开始相较之前的要小再缓慢上升
应该是存储和读取模型时的问题