GAGAvatar 学习笔记
1 Overall
GAGAvatar(Generalizable and Animatable Gaussian Avatar),一种面向单张图片驱动的可动画化头部头像重建的方法,解决了现有方法在渲染效率和泛化能力上的局限。旋转参数
现有方法的局限性:
- 基于NeRF的方法:
- 优点:在头像合成和细节(如头发、饰品)上效果优秀。
- 局限:NeRF老毛病渲染慢,实时性较差。
- 基于 3DGS 的方法:
- 优点:实现实时渲染
- 局限:针对每个 identity 需要进行特定的训练,无法推广泛化。
Contributions:
- 引入 Dual-lifting 方法及结合 3DMM 先验,解决了从单张图片构建 3D 高斯模型的难题。
- 通过预测图像平面中每个像素的 lifting 距离(即从 2D 到 3D 的深度信息)。
- 利用 forward and backward lifting 生成几乎闭合的 3D 高斯点分布,最大程度还原头部形状。
- 结合 3DMM 的先验,约束 lifting 过程,确保生成细节。
- 通过结合 3DMM 和高斯分布,既能准确传递表情信息,又避免了冗余计算。
2 Method
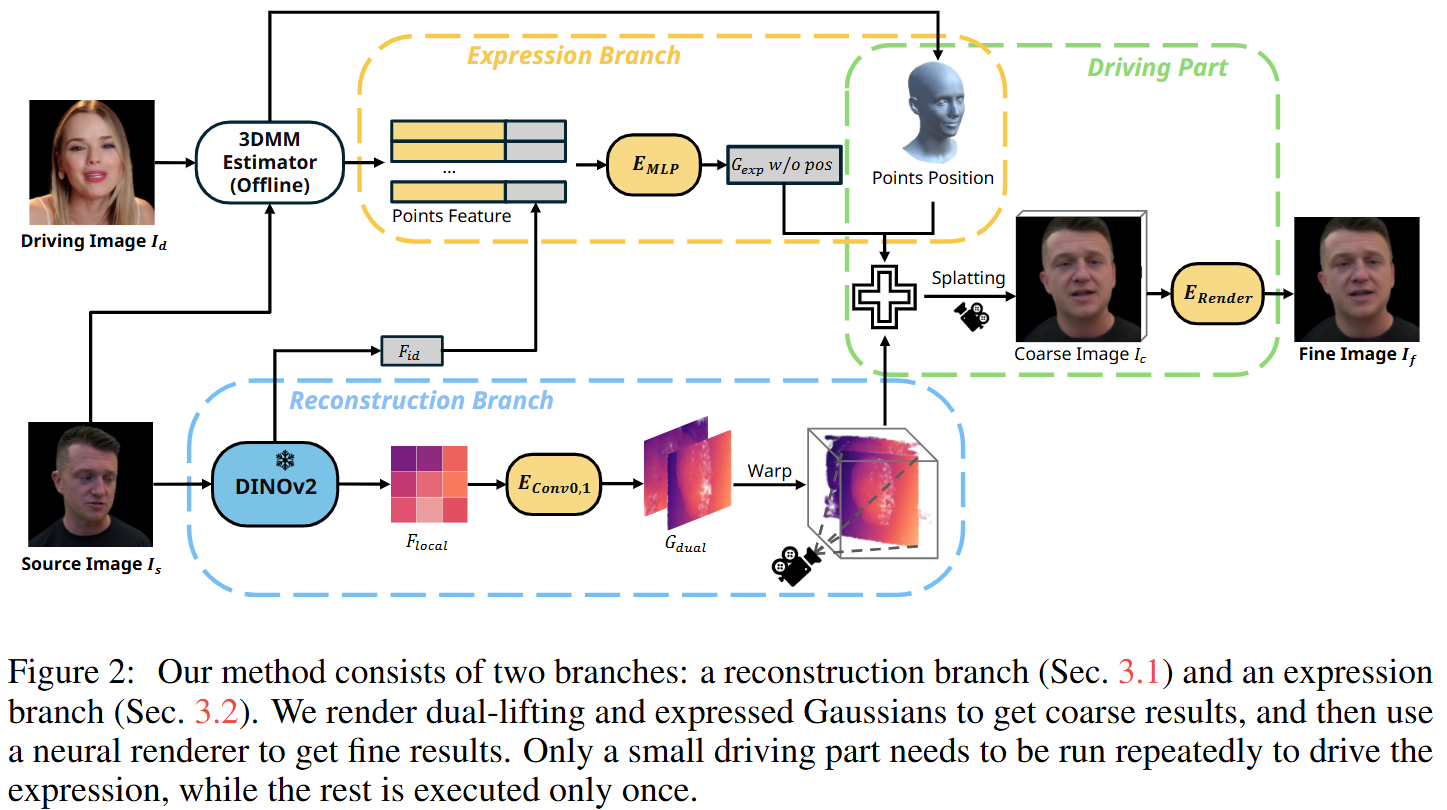
本文方法分为两个主要分支:重建分支(Reconstruction Branch)和表情控制分支(Expression Branch)
重建分支生成静态高斯点,而表达分支生成动态高斯点。
主要步骤:
- 从源图像中提取全局和局部特征,用 DINOv2 进行多尺度视觉特征提取。
- 基于局部特征,提出了双 lifting (Dual-lifting)方法,预测 3D 高斯点的位置和参数。
- 同时,结合全局特征和 3DMM 顶点特征,生成另一个表情高斯点集合。
- 将所有 3D 高斯点通过 splatting 生成粗图像 。
- 使用神经渲染器对 进行细化,生成最终结果 。
2.1 重建分支
Dual-lifting 策略:
- 在单次 lifting 方法中,模型可能无法确定将像素 lifting 到可见表面还是物体背面,导致学习过程中的歧义。双重 lifting 通过分别预测前向和后向偏移,解决了这一问题,消除歧义,稳定优化过程。最终,两组 lifting 点几乎形成封闭的高斯点分布。
过程:
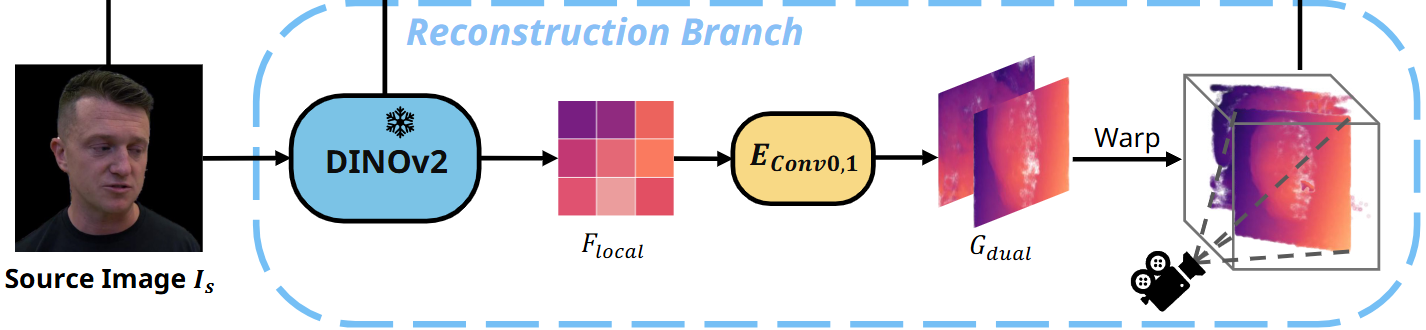
提取特征:
- 使用冻结的 DINOv2 模型提取 的局部特征平面
预测参数:不是直接预测 3D 高斯
利用两个卷积网络 和 ,分别预测每个像素相对于特征平面的前向和后向偏移量,即 lifting 距离。
参数预测:预测每个点的颜色、透明度、缩放和旋转参数
从平面到3D的映射:
- 根据相机位姿,将特征平面映射回3D空间,使其经过原点,获得平面上像素的3D位置 和法向量 (其实应该就是指向 camera,垂直于这个平面)
- 根据预测的偏移量,将平面上的点沿法向量 提升到三维空间:
2.2 表情分支
组成:
3DMM:
- 表情解耦:3DMM 可以将面部表情和身份特征解耦。这种解耦使得即使是不同身份的图像之间,也可以有效地传递表情
- 顶点语义稳定性:3DMM 的每个顶点在模型中对应固定的面部区域(如眼睛、嘴巴等),有助于精确定位和修改特定部位的表情
3D Gaussians:
- 通过 3DMM 的顶点位置生成 3D Gaussians。
- 顶点的学习权重与表情特征绑定,用于调整生成的图像中的表情。
过程:
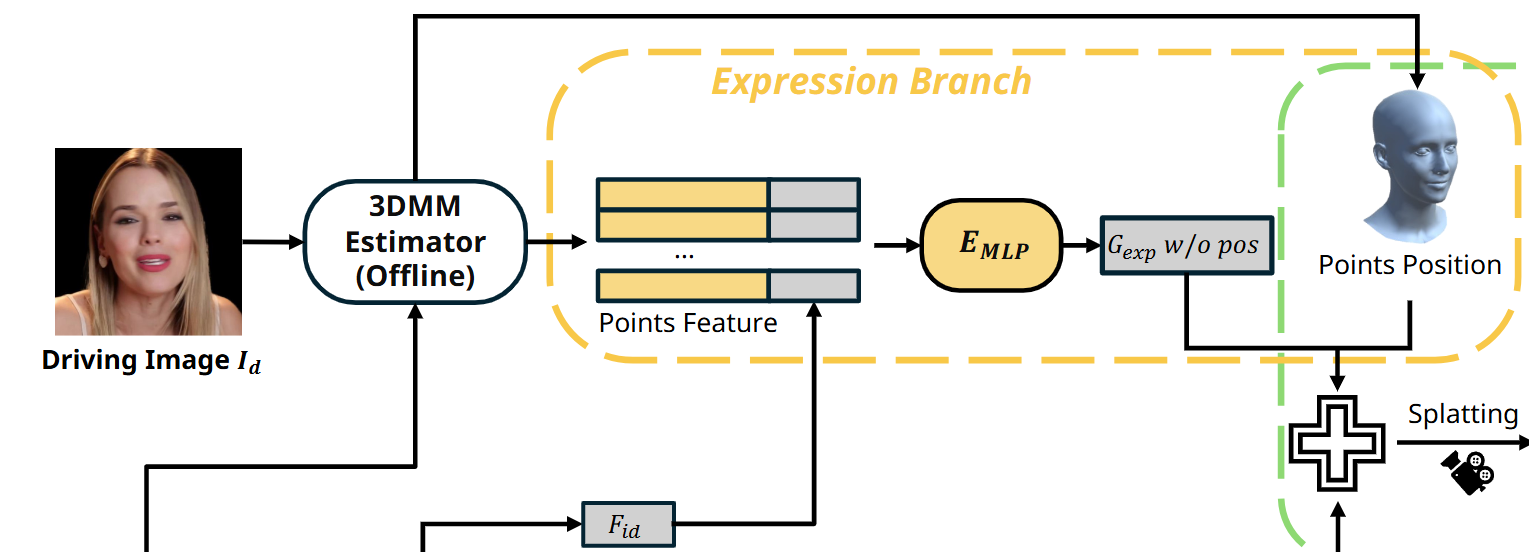
- 输入特征融合:
- 通过 DINOv2 从驱动图像 提取全局特征 (将身份信息注入表情分支,确保生成结果在表情变化的同时保持身份一致性)
- (从 Driving img 和 Source img 通过使用 GPAvatar 提供的 3DMM 估计方法(基于 EMOCA 和 MICA)提取FLAME ),将可学习的权重绑定到 3DMM 中的每个顶点,表示顶点与表情相关的特定属性(如嘴唇张开程度或眉毛上扬)得到顶点特征
- 将全局特征 和顶点特征拼接
- 高斯参数预测:使用 MLP 从拼接的特征中预测每个点除了位置外的所有高斯参数(如颜色、透明度、大小、旋转等)。
- 使用 3DMM 顶点的固定位置作为高斯点的位置输入,保持空间一致性。
高效表情驱动:
- 只需在初始阶段一次性的计算出重建分支和表情分支的高斯点。通过修改表情分支中高斯的位置和相机姿态,实现快速的表情重演,无需重复计算。那表情高斯点的其他属性为什么不需要调整?
3.3 神经渲染器
- dual-lifting 之后仅仅获得175,232个高斯点比较少,所以仅凭这些点的 RGB 信息不足以捕获人类头像的丰富细节。所以所有的高斯点的预测信息是包含RGB信息的32维特征,首先进行 splatting 以获得粗略图像。
- 神经渲染器细化:使用类似EG3D的超分辨率模块,只不过不提升分辨率而是将粗略图像(32维特征)细化为高质量的最终图像。
- 神经渲染器有效地将 dual-lifting 和表情高斯特征解码为RGB值,生成高质量的结果,并解决两组高斯之间的潜在冲突。
- 在训练过程中,从零开始训练神经渲染器,不使用任何预训练初始化。
3.4 训练策略与损失函数
使用预训练的 DINOv2 不参与训练,其余部分从零开始训练。
- 数据:随机从同一视频中抽取两帧图像,一张作为 Source img,一张作为 Driving img 和 Target img
- 目标:
- 确保生成的粗略图像 和精细图像 与目标图像 对齐。
Loss:
图像重现损失( 和感知损失):约束生成图像 (, ) 与目标图像 () 的像素和语义特征对齐。
L1 损失:直接计算像素级差异
感知损失:通过预训练的感知模型(如 VGG)提取高层次语义特征,用于比较生成图像和目标图像的感知相似性:
其中 表示感知模型提取的特征。
Lifting 距离损失( ):帮助模型更准确地学习 Dual-lifting 的 3D 点位置,从而增强重建的3D结构和视角变化能力。
方法:使用 3DMM 提供的先验信息(顶点位置 )约束双重提升生成的高斯点 () 中最近的点与 3DMM 顶点的距离尽可能小。即通过 L2 损失计算顶点和最近点的距离。
:3DMM 的顶点集合
:双重提升生成的高斯点集合
:找到距离每个 3DMM 顶点最近的高斯点
特点:只对部分高斯点施加约束(与 3DMM 顶点对应的部分),允许模型学习未被 3DMM 覆盖的区域(如头发、饰品等),增强生成图像的细节表现力。
3 Limitations
新视角未见区域的细节不足:
生成结果可能是基于统计学上的“平均期望”,而非真实的细节例如:
- 从侧脸视角生成另一半脸部时,缺乏真实的细节。
- 从闭嘴图像生成张嘴状态时,生成结果可能不够逼真。
原因:合成过程中缺乏对未见区域的具体信息,导致生成效果趋于平均化。
解决方向:引入随机生成模型(如 diffusion),通过增加生成的随机性提高未见区域的细节表现。
表情分支的限制:
- 依赖 3DMM:表情分支基于 3DMM 模型进行训练,而 3DMM 具有一定的局限性,无法完全覆盖所有面部细节。
- 极端表情难以处理:如一只眼睛闭合而另一只眼睛睁开、舌头的动态或头发细节。
- 数据集限制:表情分支从 VFHQ 视频数据中学习,可能不足以捕获极端的面部运动或未被 3DMM 模型覆盖的区域。
解决方向:不依赖 3DMM,从图像中直接提取表情嵌入。—— 需要一个好的