Can We Generate Images with CoT? 学习笔记
1 Overview
https://arxiv.org/abs/2501.13926
将 CoT 推理策略从语言任务迁移到自回归图像生成中
自回归图像生成与语言生成在“逐token生成”的机制上高度相似,为应用CoT提供了潜在可行性
Show-o 的图像生成方式本质上是一种基于 mask 的 iterative denoising 机制,但操作在 token 层级 而不是 pixel 层级
- 每一轮输出都能还原出一张中间图像(虽然部分 token 还是 mask)
👀但是看下来,跟 Autoregressive 的的范式没什么关系,Diffusion 也能这样做吧;这更应该归为通用生成中的 reward 引导与路径优化机制
更新:已经有用 GRPO 做出类似想法的工作了:Flow-GRPO
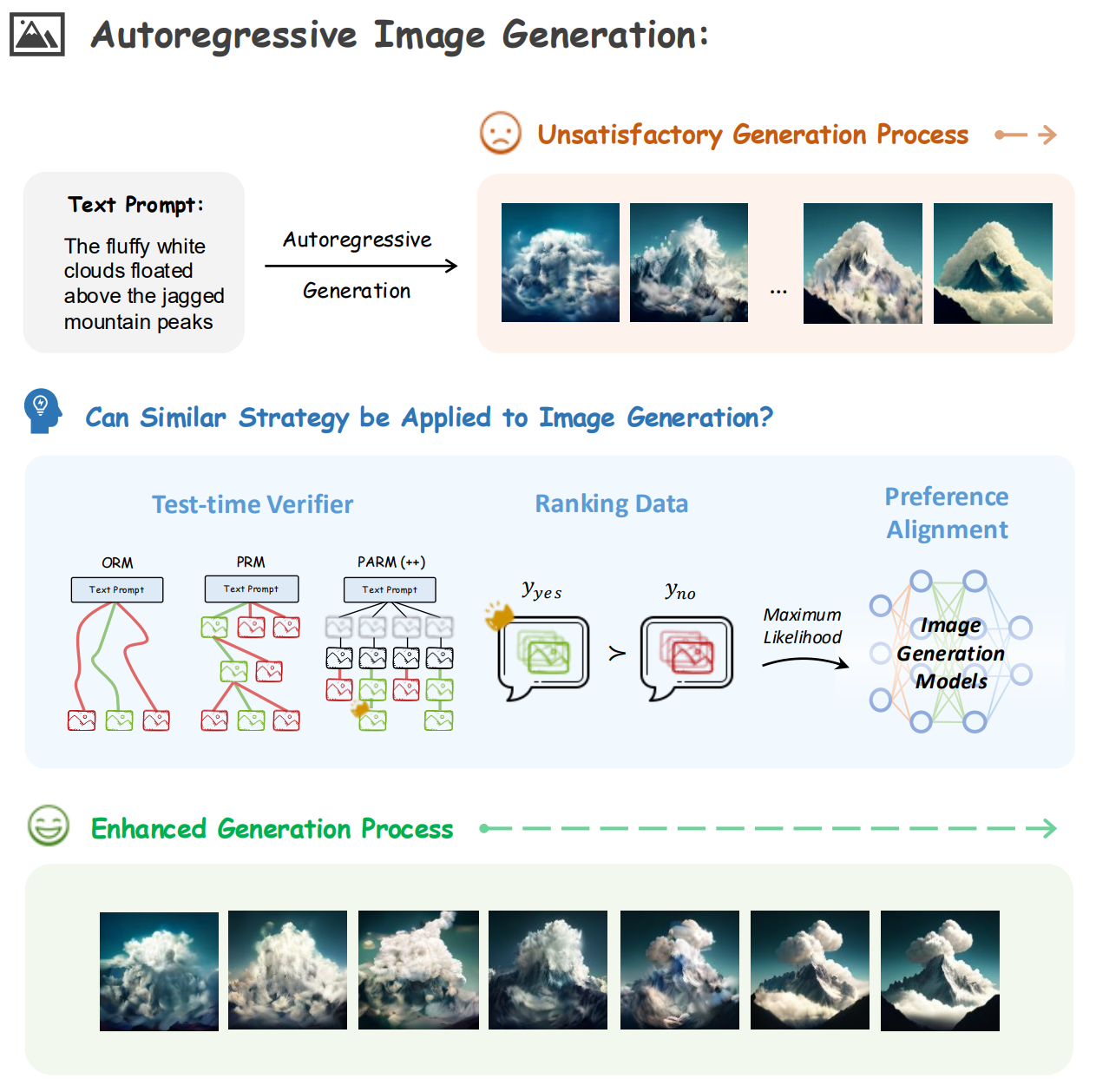
探索了两大类增强策略:
测试时验证(test-time verification):利用Reward Model(ORM 和 PRM)挑选生成结果
- ORM 显著提升结果,而PRM效果有限
偏好对齐(preference alignment):利用DPO(Direct Preference Optimization)优化生成策略
- DPO 对齐优于仅使用 Reward Model
当时还没有 GRPO 改进 ORM/PRM:
PARM:三步式潜力评估机制,解决 PRM 早期图模糊与 ORM 全局评估不准的问题
PARM++:在 PARM 基础上引入反思机制,对生成失败图像进行自我纠错与重生成
使用 Show-o 作为主干
2 Method
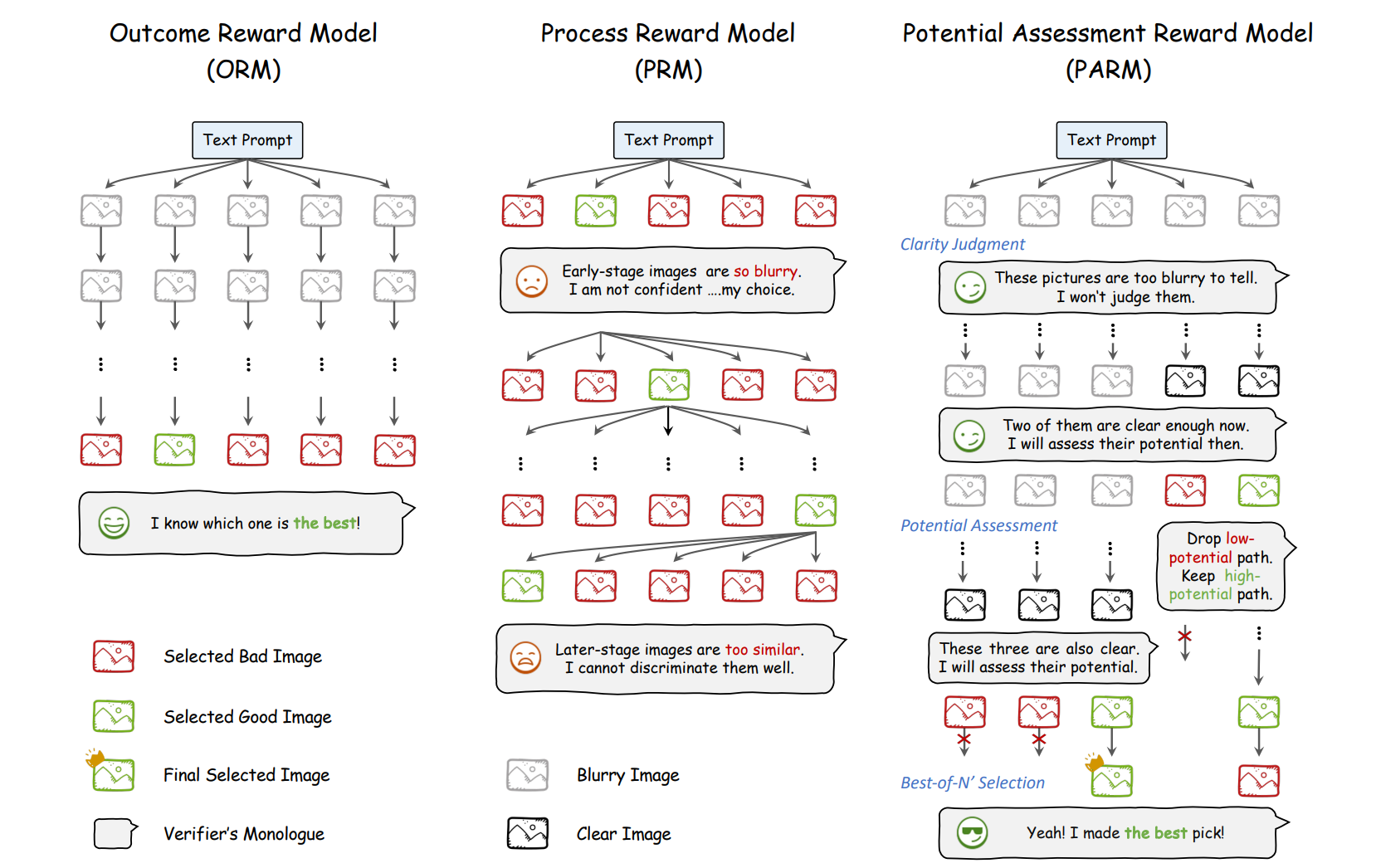
2.1 DPO+ORM
具体做法:
ORM:只在生成完成后评估图像是否符合 prompt —— 聚焦最终结果,图像清晰,语义完整,评估准确
- 使用预训练的 LLaVA-OneVision-7B 作为 Zero-shot ORM
- 通过 prompt template 输入“文字+生成图” → 模型输出 “yes”/“no”
- 用“yes”概率最大的作为最终输出(best-of-N)
- 构造 288K 的图文对比数据集(使用 GPT-4 生成 prompt,Show-o 生成图像,人工/自动打标签)进行 fine-tune → 提升 ORM 判断能力
PRM:在生成过程中的每一步图像都进行打分 —— 前期图像模糊,难评估;后期图像差异小,难区分。
- 同样从 LLaVA-OneVision 开始 zero-shot
- 构造 1 万个 step-wise 的图文序列做精调
DPO:基于之前用于训练 ORM 的“好图/坏图”二分类数据,构建了 DPO 所需的偏好排序对(preferred/dispreferred pairs)
- policy model:从 Show-o 初始化,并在训练中更新
- reference model:也来自 Show-o,但保持冻结
- 优化目标:鼓励策略模型对更优图像(preferred)赋予更高概率
DPO+ORM:1 < 2 < 3
- DPO + ORM guidance:ORM 为 DPO 时 reward model(DPO 训练时,不仅使用 ranking pairs 进行 loss 计算,还引入 ORM 的输出作为奖励信号)
- DPO + test-time ORM:普通 DPO 后,再用 ORM 在推理时做 best-of-N 策略挑选
- DPO with guidance + test-time ORM:训练时就引入 ORM 做 reward guidance,同时推理时也使用 ORM 做筛选(最好的)
2.2 PARM 和 PARM++
PARM = reward + filtering;PARM++ = reward + filtering + self-correction
PARM:
Clarity Judgment:
- 在生成的每一步,判断当前图像是否足够清晰,如果太模糊就跳过评分
- 解决了 PRM early-stage 图像没法评判的问题
Potential Assessment:
- 对通过 clarity 判断的步骤,做二值潜力判断:这个中间状态有没有可能发展成高质量结果?
- 如果潜力低,直接截断该路径(early termination)
Best-of-N′ Selection
在所有剩下的 high-potential 路径中(数量为 N′),做一个类似 ORM 的最终打分选最优
如果没有路径通过,则选 “拒绝最多次”的路径(最不被否定的)
PRM 太早评分 → 噪声;ORM 太晚评分 → 粗粒度,不可控
而 PARM 是中间可插入型 reward:既能 early exit 又能 final pick
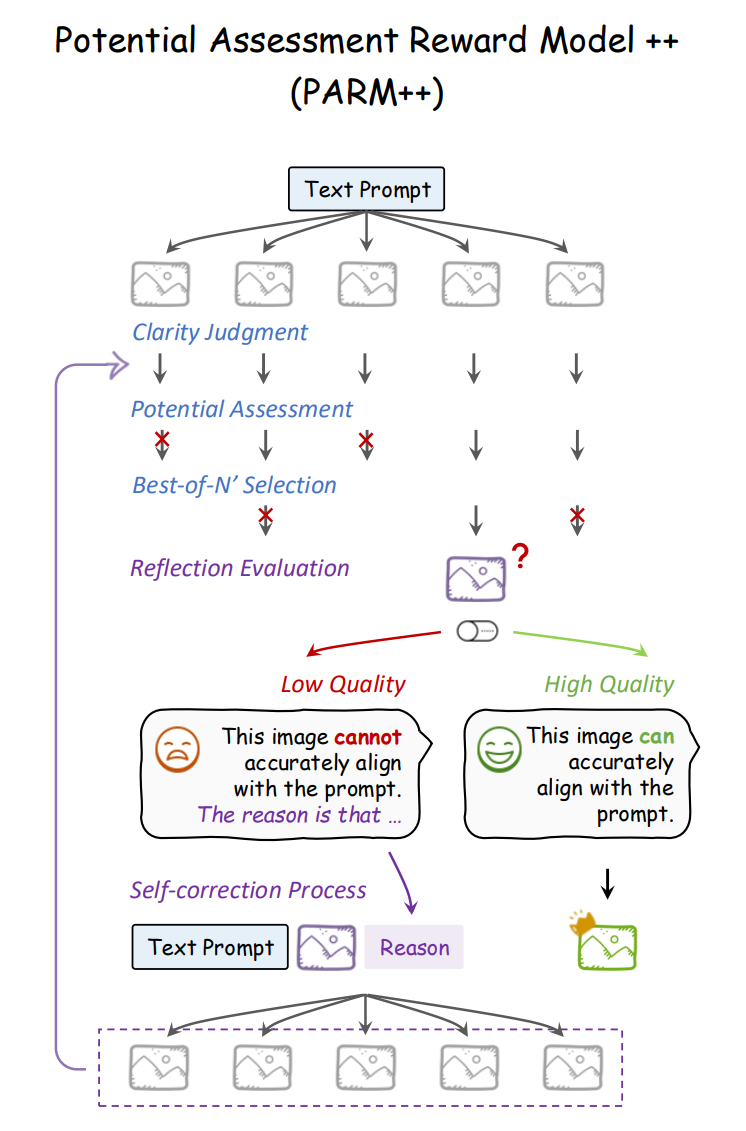
PARM++:
Reflection Evaluation:由 PARM++ 来判断最终图像是否与文本 prompt 对齐:
- 若对齐:返回 “yes” → 成品图像
- 若不对齐:返回 “no” 并附上文本说明哪里错了(如颜色错误、布局问题)
模拟人类自我检查:做完图再看一眼,“这和我要求的像吗?哪里出错?”
Self-Correction:输入三样东西给图像生成模型:
- 原始文本 prompt
- 上一轮失败的图像
- 反思输出的错误分析(文本)
然后模型尝试根据反馈重新生成图像,最多迭代 3 轮
为修正机制专门训练模型:因为 Show-o 一开始并不会“根据文本纠正图像”,所以额外训练了 self-correction 能力:
训练数据来自 PARM++:包含(text, 差图, 好图, 错误分析)四元组
用这批数据微调 Show-o,让它学会根据错误提示优化生成质量
📌 DPO 与 PARM++ 的兼容性问题:
在 PARM++ 实验中没有使用 DPO 对齐,原因是 self-correction 微调和 DPO 的目标可能冲突,如果同时做,可能会导致训练干扰或过拟合到某一目标
- DPO 是 preference alignment:目标是让模型输出“人更喜欢”的图像
- PARM++ 的 self-correction 微调:目标是让模型“听懂改图建议并动手改图”
PARM++ 开启反思机制后,相比 PARM 提高了 +10% GenEval 分数
微调后的 Show-o 在原始 GenEval 上略有下降 -2%
- 说明模型在学习自我修正能力时略微牺牲了原始泛化性(但可接受)
2.3 适用建议
- 如果目标是一次性生成最优图像 →
DPO + ORM或PARM - 如果目标是质量控制 + 迭代优化图像内容 →
PARM++更优,尤其适合需要多轮 refinement 的任务