Portrait4D 学习笔记
1 Method
1.1 总体
- 目标:学习一个模型,能够从源图像 和驱动图像 中提取外观和动作信息,合成出具有 外观和 动作的3D人头。
- 3D表示:采用基于 Tri-plane 的 NeRF 作为底层的3D表示方式,兼具高保真度和高效率。
- 核心组件:
- GenHead模型 :用于合成多视角、多 identitiy 、多 motion 的人头图像,提供训练数据。
- 可动画化的 Tri-plane 重建器 :从单张图像直接重建4D人头NeRF模型。
1.2 GenHead模型
将单目图像数据转换成4D数据,以支持后续的4D NeRF重建的学习。
其实这样在 EG3D 基础上使用 3DMM 的方法生成出来的数据难以表现出像真实图像的一样的细节,导致最后与真实数据相比,用于训练的数据不够生动,这一点会在 Portrait4Dv2 中改善,其舍弃了这个 GenHead 模型
方法:在 EG3D 的基础上增加了一个局部形变场。现有的人头GAN模型无法实现对面部、眼睛、嘴巴和脖子的全面运动控制。
- 提出了一个局部生成模型 GenHead,用于处理复杂的人头动画。模型组成:
- **局部 Tri-plane 生成器 **:用于合成规范的人头NeRF。
- **局部形变场 **:用于对规范人头进行形变,实现动画效果。
1.2.1 局部 Tri-plane 生成器
网络架构:使用 StyleGAN2 作为骨干网络。
输入:
- 随机噪声
- FLAME模型的形状编码
输出:
- 头部区域的 Tri-plane
- 眼睛和嘴巴区域的 Tri-plane
1.2.2 局部形变场
通过形变将观测空间中的点 映射到规范空间,以获取相应特征。
- 输入:
- 观测空间中的点
- 形状编码
- FLAME的表情编码
- 姿态编码
- 输出:
- 局部3D形变
实现方法:使用FLAME网格 :
计算 与平均脸网格 之间的形变,其中 表示张开嘴巴的规范姿态。
对于自由空间中的点 ,根据其最近顶点的形变,使用加权平均方法推导出形变 和 。
对于 (头部形变):不考虑眼睛注视方向 。
对于 (眼睛和嘴巴形变):
眼睛区域:使用包含表情编码的形变 。
嘴巴区域:使用不包含表情编码的形变 ,以处理表情引起的嘴唇和牙齿的相对运动。
1.2.3 4D数据合成
特征提取与渲染
- 特征提取:从 Tri-plane 和 获取特征 和 。
- 体渲染:使用体渲染方法分别渲染出两个特征图。
- 融合:使用基于 的光栅化掩模在视角 下融合渲染的特征图。
背景生成与最终合成
- 背景生成:使用另一个 StyleGAN2 生成2D背景图像 。
- 图像融合:将渲染的前景图像 与背景 融合。
- 超分辨率处理:将融合后的图像输入2D超分辨率模块,生成最终高分辨率图像。
对抗训练:参考EG3D
4D数据合成:
动作和视角参数的提取:
- 使用现有的 3DMM 重建方法从单目图像和视频中提取 3D 参数,为了提高准确性,进一步利用基于关键点的优化方法对这些参数进行微调。包括:
- 形状 、表情 、姿态 、摄像机视角
- 使用现有的 3DMM 重建方法从单目图像和视频中提取 3D 参数,为了提高准确性,进一步利用基于关键点的优化方法对这些参数进行微调。包括:
动态数据的构造(不同视角的动态头像):用于学习头部动作 reenactment,动作和视角的多样性帮助模型学习复杂场景中的头部动画。
- 随机组合生成 identitiy
- 为每个 identitiy 分配从同一视频片段中提取的表情
- 为每个动作分配随机的摄像机视角
静态数据的构造(不同视角的静止头像):用于提升 3D 重建的泛化能力。更专注于头部静态几何形状的重建,去除动态因素的干扰。
- 类似地生成随机 identitiy ,但每个 identitiy 仅对应一个随机动作 ,并分配多个视角 。
在生成 4D 数据时,GenHead 提供了中间结果作为额外的监督信号,包括:
- 三平面特征 :表示 3D 点在三平面上的投影特征。
- 低分辨率渲染图 $\bar{I}_f $ 和 :包括前景特征图和背景图。
- 深度图 :提供几何深度信息。
- 不透明度图 :用于分离前景和背景。
1.3 Tri-plane 重建器
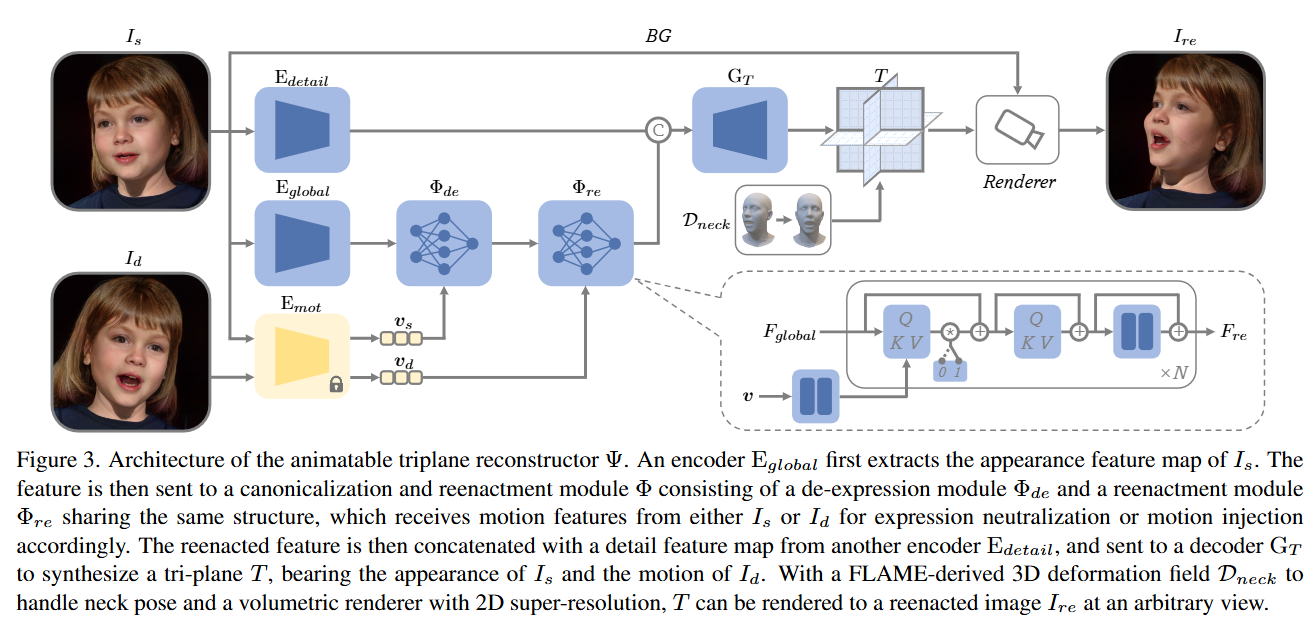
实现头部 reenactment,将源图像的 identitiy 和驱动图像的动作 融合,生成具有源外观和驱动动作的目标图像。
- :负责从源图像和驱动图像重建 Tri-plane 。
- :渲染器,用于将 渲染为特定视角 下的图像 。
1.3.1 组成
外观编码器 和 :采用中 Live 3D Portrait 的 CNN 结构
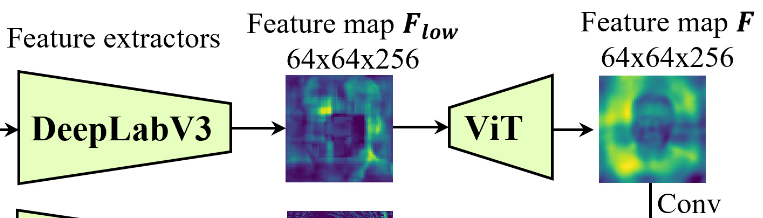
是一个 CNN & ViT 是来自 Segformer 的 ViT Block,具有高效的自注意力机制
- :提取 的全局外观特征
- :提取局部细节特征 ,在解码阶段补充精细信息
动作编码器 :直接使用的 PD-FGC
用于从 提取动作向量 。 包括 identitiy 无关的动画信息,优于传统的 FLAME 表情参数 。
是要冻结的,因为假设其是能训练的,当把驱动的图片输入进去,会导致他过拟合到驱动图片上(因为监督的图片就是驱动图片)
特征规范化与再现模块 :
- :规范化 ,消除 表情信息。(可以避免模型的注意力层过度拟合,提升泛化能力)
- :注入 的动作信息,再现目标动作。
结构:两个基于 Transformer 的模块,具有相同的结构,包含多个 Transformer 块,包括:
- 交叉注意力层:全局特征图提供 Queries ,动作特征提供 Keys 和 Values,实现表情中和和动作注入
- 自注意力层:处理全局特征图内部的依赖关系。
- MLP:用于姿态规范化。
学习解耦:通过将所有交叉注意力层的输出乘以零或不乘以零,实现3D重建和 reenactment 过程的解耦。提高模型在真实图像上的泛化能力。
Tri-plane 解码器 :
- 将再现后的特征 和细节特征 结合,解码生成
1.3.2 渲染流程
- 提取全局外观特征 和局部细节特征
- 经 消除表情,再由 融入 的动作信息,生成再现特征
- 与 结合,通过 生成Tri-plane
- 应用FLAME衍生的变形场 处理颈部姿态旋转,简化为几乎均匀的刚性变换,无需高精度的3DMM重建。
- 使用浅层U-Net预测2D背景特征图 。将渲染的前景图像 与背景 融合,生成最终图像。
1.4 解耦学习
除固定的动作编码器 外,整体重建器 使用 GenHead 的合成数据进行端到端训练。
1.4.1 训练合成模型 的方法
自我 reenactment 训练方式:
- 随机选择两张具有相同 identitiy 的图像,分别记为 和
- 选择另一张有 的 identitiy 和动作但是不同视角的图像作为真实再现图像
- 训练目标是让模型生成的重现图像 在内容上匹配
1.4.2 解耦学习策略
将模型从仅依赖合成数据的训练扩展到能够泛化到真实数据。
问题:
模型中过多依赖 中的自注意力和 MLP 层来处理表情去除和姿态规范化,导致对合成数据的过拟合,降低对真实图像的泛化能力。
解决方案:
解耦自注意力和 MLP 层:仅让自注意力和 MLP 层专注于姿态规范化。让交叉注意力层处理所有与动作相关的过程。
实现方式:随机以一定概率对跨注意力层的输出乘以零,使网络退化为静态 3D 重建任务,同时使用静态数据来执行退化任务
动态数据则用于正常的动作重现训练。
效果:通过这种随机退化策略,网络的不同部分被迫专注于特定任务,从而实现对重建与重现的学习解耦。
1.4.3 Loss
是多个损失函数的加权和
重现损失 :计算生成图像 与目标图像 之间的感知差异和 距离
特征图损失 :计算 、 与其对应的目标特征图的 距离。
三平面损失 :比较采样三平面特征 与目标特征 的 距离。
注意: 和 GenHead 的三平面代表不同的几何,因此不能直接比较。
深度图损失 :比较深度图 和目标深度图 的 距离。
透明度图损失 :比较透明度图 和目标透明度图 的 距离。
身份损失 :使用面部识别特征 ArcFace 计算 和 的负余弦相似度。
对抗损失 :利用 GenHead 的鉴别器,对 和 执行对抗性学习。
2 Limitations
训练数据的局限:
- GenHead 数据合成依赖于 3DMM 模型来控制表情,这些生成的表情与真实数据相比可能不够生动。
原因:3DMM 基于简单线性模型,缺乏对复杂表情的细腻控制。
在 Portrait4Dv2 得到了解决:使用伪多视角视频来学习4D头像合成器
采用两阶段学习方法:
- 先学习3D头像合成器,用于将单目视频转换为多视角视频
- 再利用生成的伪多视角视频通过跨视角 self-reenactment 来学习4D头像合成器
复杂配饰和妆容:
- 模型在处理复杂配饰(如帽子、耳环)和浓重妆容时表现不佳 。
- 背景中高频细节的重建能力不足。
潜在改进:增加体渲染的分辨率,可以让信息流更细致,同时减轻 2D 超分辨率模块导致的纹理闪烁问题。
大角度侧脸图像:
- 当输入图像为接近侧脸的大偏航角度图像时,模型表现较差,主要因为训练数据分布不均。
特定表情的伪影:
- 对于特定表情(如眨眼),模型可能生成伪影。这是因为 GenHead 数据主要来源于 FFHQ 数据集,该数据集包含较少闭眼的图像。
改进方向:引入包含更多多样表情和姿态的数据以增强模型的泛化能力。
4D 数据合成与训练挑战:
- 合成高质量 4D 数据需要提前训练可动画的 3D GAN,这一过程本身具有挑战性。
- GAN 模型可能面临模态丢失的问题,导致生成数据的多样性受限。
- 与静态 3D 数据相比,使用 4D 数据训练更容易过拟合。
未来方向:
- 生成更高质量和多样性的 4D 数据以支持一次性重建流程。
- 探索将真实数据与 3D 先验(如 3DMM 或深度图)结合的端到端训练方法。
- 扩展当前管道,支持少样本学习,以更高效利用训练数据。