Portrait4D-v2 学习笔记
1 Overall
作者提出了一种基于伪多视角视频的学习框架,绕过了不准确的3DMM重建的高度依赖(Portrait4Dv1 的 Limitation),核心思路是:
- 伪多视角数据生成:从单目视频生成多视角数据,使用的是一个预先训练的3D生成器(通过静态3D头像的新视角合成)。
- 采用两阶段学习方法:
- 仅学习静态三平面重建:先学习3D头像合成器,用于将单目视频转换为多视角视频
- 激活运动相关组件,学习完整模型:再利用生成的伪多视角视频通过跨视角自重演来学习4D头像合成器
2 Method
从单张源图像 生成一个可动画的3D头部表示(Tri-plane ),其中:
- 能够真实还原源图像的外观
- 头部的动作模仿驱动图像 中的表情和姿态
采用了 Portrait4D 的前馈骨干结构,通过基于 Transformer 的重构器 预测 。为了让 学习逼真的头像生成能力,本文提出用伪多视角视频来进行监督训练,方法包括两步:
- 学习一个3D头部生成器 ,从单目视频生成新视角帧
- 利用生成的多视角视频进行 cross-view self-reenactment 训练
2.1 Portrait4D 回顾
Portrait4Dv1 的结构:
- 基于 CNN 和 ViT 的混合结构。
- 主要流程:
- 两个 CNN 编码器分别提取源图像的全局特征和细节特征
- 全局特征输入到多个 ViT 块中进行姿态标准化
- 将标准化后的全局特征与细节特征拼接,输入到带有卷积的 ViT 解码器,生成最终的 Tri-plane 表示
- 动作信息注入:
- 引入 cross-attention,分布在每个标准化 ViT 块中。
- 在前几层,跨注意力接收源图像的动作嵌入 用于表情中和
- 后几层接收驱动图像的动作嵌入 用于再现动作
将 Portrait4Dv1 删除与 motion 相关的交叉注意力机制,退化为静态3D生成器能很好地泛化到真实图像,捕捉到细腻的面部表情,这些细节超出传统 3DMM 的表达能力。
所以,与其像 Portrait4Dv1 先生成 4D 数据进行监督,不如先训练一个静态 3D生成器 ,并用它从单目视频生成伪多视角帧。
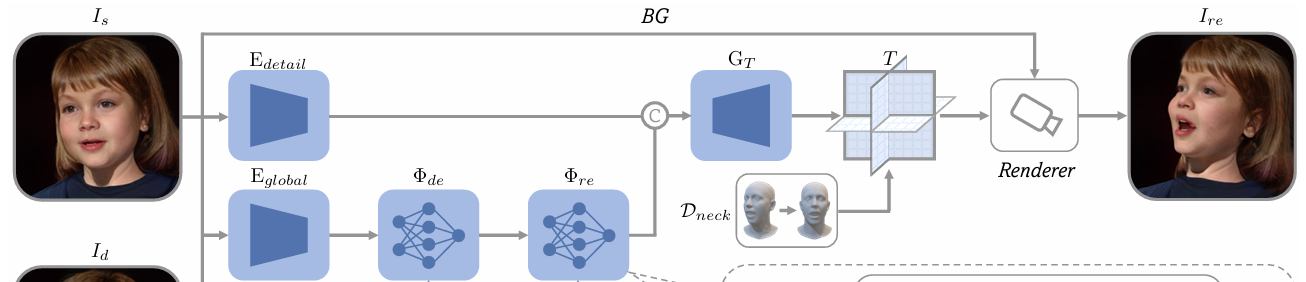
2.2 用于多视角视频生成的3D合成器
即训练一个退化为3D合成器的 Portrait4Dv1,整体流程与 Portrait4Dv1 一致。
学习一个 3D头部合成器,将任意单帧图像转换为对应的 Tri-plane 表示,以支持自由视角渲染生成伪多视角帧。
结构:使用 Portrait4D 的 ,但禁用了所有交叉注意力层,使其退化为3D重建器
训练数据:GenHead 生成的伪多视角数据(Portrait4Dv1 的静态数据的构造)
- 从现成的 3DMM 重建器对真实图像进行特征提取,得到 FLAME 参数 ,分别表示形状、表情和姿态编码。
- 随机采样一个 参数组,并结合高斯噪声 作为输入,利用 GenHead 生成任意 3D头像。
- 随机采样相机外参 ,渲染生成的 3D头像的多视角图像 。
训练 :输入一个视角图像 , 能够重建输入对应的三平面 ,并保证它在另一视角下渲染的结果 与真值一致。
2.3 跨视角Self-Reenactment学习
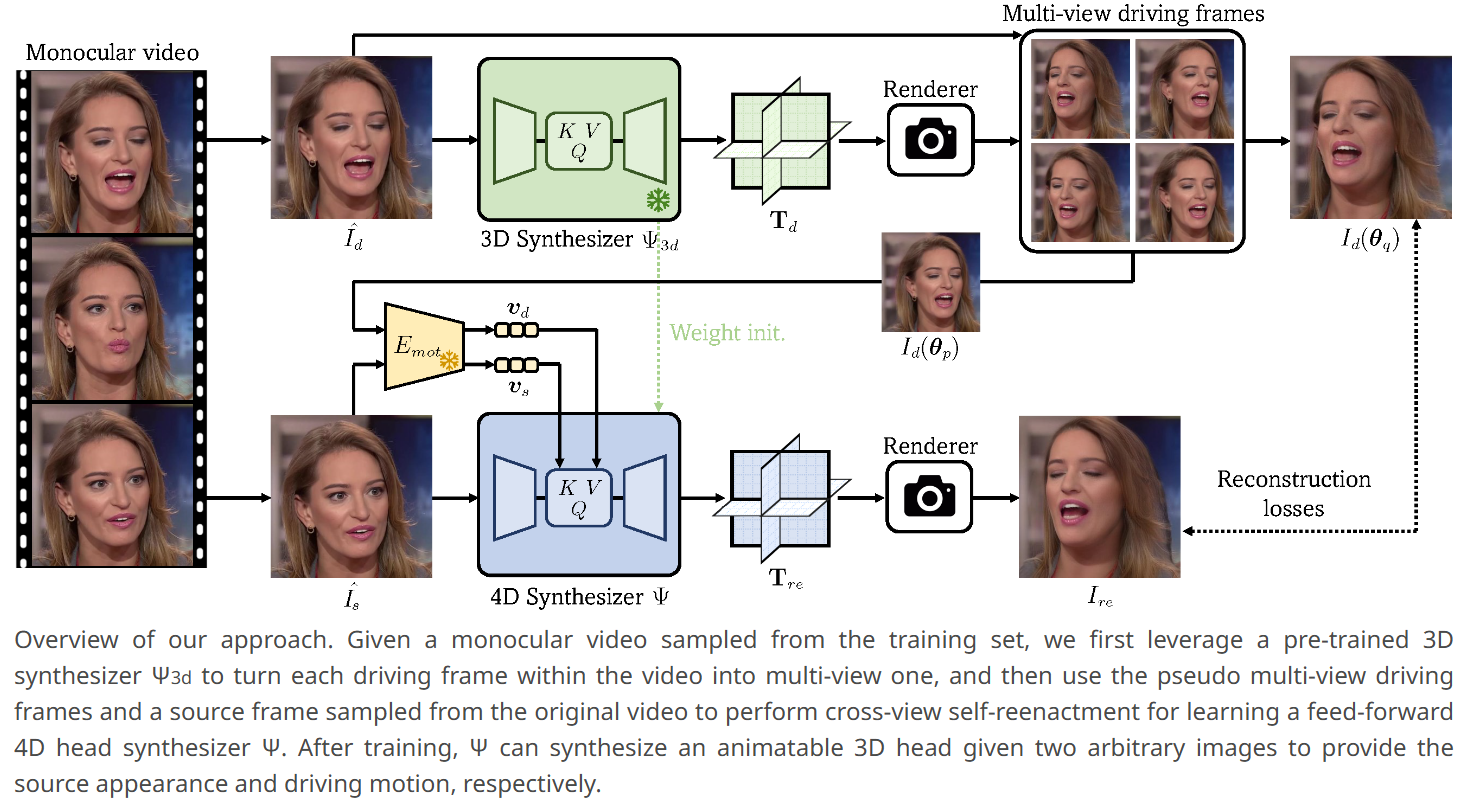
2.3.1 训练
的结构与 Portrait4Dv1的应该是一致的
先使用 3D合成器 预先训练的权重来初始化4D合成器 (除了与 motion 相关的交叉注意层),这使得 从 学到几何和外观的先验知识,使得复演图像 能更好地重建未见区域的细节。
随机选取:
- 源帧:(从真实视频 中抽取)
- 驱动图像对: 和 (从伪多视角数据 中抽取,表示同一动作在不同视角下的图像)
使用合成器 :
输入:源图像 和驱动图像 。
输出:复演图像 ,其视角与 对应:
- :分别由运动编码器 (PD-FGC)从源图像 和驱动图像 中提取的运动嵌入。
是要冻结的,因为假设其是能训练的,当把驱动的图片输入进去,会导致他过拟合到驱动图片上(因为监督的图片就是驱动图片)
2.3.2 真实帧与伪视角帧的替换机制
考虑到伪多视角数据 和 由 $ \Psi_{3d} $ 合成,可能存在还是有瑕疵:
- 替换 :概率为 80%,重点训练 reenactment 真实帧的能力。
- 替换 :概率为 10%,比较小的概率是因为该图像主要用于提取高层次运动嵌入,就算一些瑕疵也对合成器的影响较小。
该策略使得伪多视角数据更专注于提供几何正则化,而真实视频帧用于更精细的图像重建。
2.3.3 损失函数
定义复演损失 来约束复演结果 与目标图像 的一致性:
- :像素级 损失,确保图像细节的一致性
- :感知损失,用于优化图像的视觉相似性
- :身份损失,衡量人脸识别特征的一致性
- :对抗损失,提高生成图像的真实性
当目标图像为真实视频帧 时,计算所有损失项;若目标为伪多视角图像 ,仅计算 ,以更多地发挥其几何正则化作用。
3 Limitations
- 局限性:当前使用的 使用 PD-FGC 是用 VoxCeleb2 数据集训练的,该数据集可能缺乏极端表情(如鼓腮或伸舌)。导致算法对夸张的面部动作捕捉不足。
- 改进方向:重新训练运动嵌入,采用更具表现力的数据集。替换为更高级的运动嵌入方案以提高表情模仿的精确度。
- 新视角区域细节不足:在合成的新视角图像中,原始源图像中未见的区域通常细节较少。因为4D头部合成器具有确定性,它倾向于预测所有可能结果的“平均期望”,导致细节缺失。
- 解决方向:引入随机生成模型(如 diffusion),通过增加生成的随机性提高未见区域的细节表现。
- 数据分布的局限性:对分布外数据表现较差。不同种族身份的生成质量可能略有差异。
- 改进方向:收集更加多样化、高覆盖率的训练数据。提高模型对不同种族、身份的泛化能力。