EG3D 学习笔记
1 Contributions
混合显式-隐式网络架构:提出了一种 Tri-plane 的3D表征方法,结合显式体素网格与隐式解码器的优点
- 速度快,内存效率高;
- 支持高分辨率生成,保持3D表征的灵活性和表达能力。
- 与纯显式或隐式方法相比,既解决了查询速度慢的问题,又能更好地扩展到高分辨率。
使用超分辨率模块 Super Resolution :解决高分辨率训练和渲染的计算限制。
双鉴别器 dual-discrimination:在生成器的渲染结果与最终输出之间引入双重判别器,增强了神经渲染与最终输出之间的一致性,避免了视图不一致的问题。即将超分辨率之前的图像和超分辨率之后的拼在一起鉴别。
姿态条件生成 pose-based conditioning to the generator:
引入基于姿态的条件生成方法,使生成器在推理时能输出与多视图一致的图像。
同时,能够很好建模训练数据中与姿态相关的属性分布(如人脸表情的变化)。
特征生成与神经渲染的解耦:
- 利用2D GAN(如StyleGAN2)的特征生成器,结合3D神经体积渲染,提高效率和效果。
2 Related Works
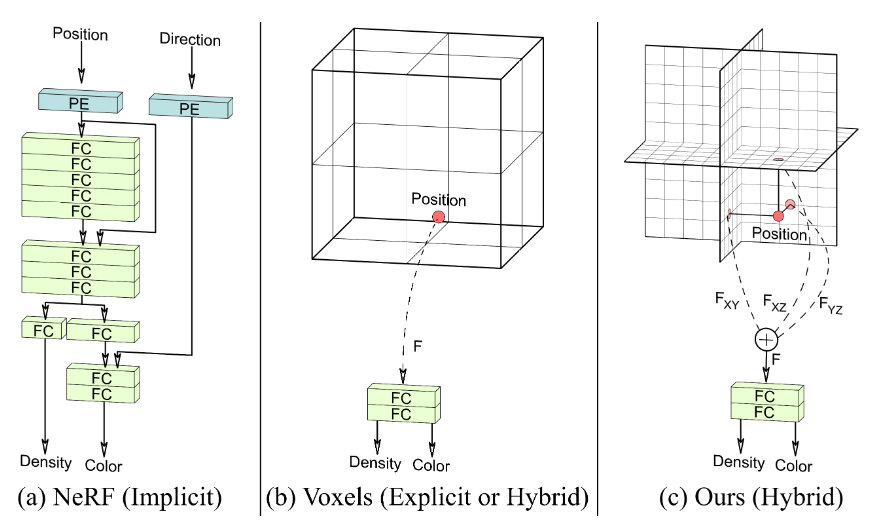
- 隐式表示(NeRF):这些方法需要大型的全连接网络,每次查询都需要完整的网络计算,速度慢。
- 显式表示(Voxels):评估速度快,但内存开销大,难以扩展到高分辨率或复杂场景。
- 混合显式-隐式表示:结合了以上两种方法的优点,提供了计算和内存效率更高的架构。局部隐式表示和混合架构通过在显式存储的基础上,使用隐式解码器来聚合特征,从而实现高效的渲染。
3 Method
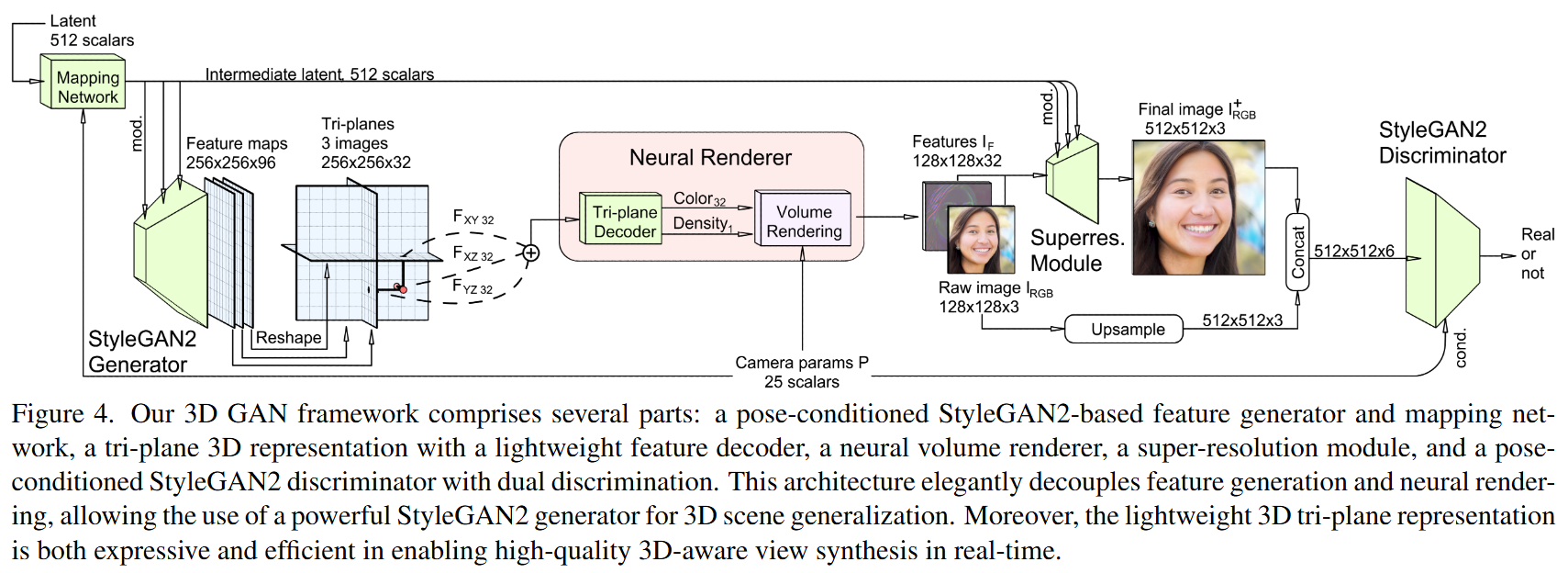
Tri-plane特征的生成:
- 在GAN设置中,Tri-plane特征是由2D卷积的StyleGAN2骨干网络生成的。
- 每个Tri-plane包含32个通道,共96个通道。
神经渲染和超分辨率模块:
- 在GAN设置中,神经渲染器从每个32通道的Tri-plane中聚合特征,预测出给定相机姿态下的32通道特征图像。
- 随后,通过一个“超分辨率”模块对这些神经渲染的原始图像进行上采样和细化。
判别器:
- 生成的图像由稍微修改的StyleGAN2判别器进行评判。
训练策略:
- 加速训练
- 首先,以较低的神经渲染分辨率(64×64)进行训练;
- 然后,在完整的神经渲染分辨率(128×128)上进行短时间的微调。
- 正则化:额外的实验发现,对密度场的光滑度进行正则化有助于减少3D形状中的伪影
3.1 Tri-plane混合3D表示
作者提出了一种新的 Tri-plane 混合显式-隐式3D表示方法
- Tri-plane 表示:将3D空间的特征投影到三个轴对齐的正交平面(XY、XZ、YZ平面),每个平面具有尺寸为 N×N×C,其中 N 是分辨率,C 是通道数。
- 特征查询和聚合:对于任意的3D点,通过在三个平面上进行双线性插值获取特征,然后将这些特征向量相加,得到聚合的3D特征。
- 轻量级解码器:使用小型的MLP解码器将聚合的特征转换为颜色和密度信息。
- 体渲染:通过神经体渲染生成最终的图像。
优势:
- 高效性:相比于完全隐式的表示,减少了计算成本,因为解码器更小,主要的计算集中在显式存储的特征上。
- 表现力:尽管表示紧凑,但仍具有足够的表达能力,能够捕捉复杂的细节。
- 扩展性:特征平面的存储需求为 O(N²),而体素网格为 O(N³),因此在相同内存条件下,Tri-plane表示可以使用更高的分辨率。
3.2 CNN生成器骨干网络与渲染
Tri-plane 特征的生成:
- 在GAN设置中,Tri-plane 表示的特征是由StyleGAN2 CNN生成器生成的。
- 随机潜码和相机参数首先通过一个映射网络处理,得到中间潜码,用于调制一个单独的合成网络的卷积核。
输出形状的修改:
修改了StyleGAN2骨干网络的输出形状:不再生成三通道的RGB图像,而是生成一个256×256×96的特征图像。这个特征图像在通道维度上拆分并重塑,形成三个32通道的平面(对应于Tri-plane表示)。
特征采样与解码:
- 从Tri-plane中采样特征,通过求和进行聚合。
- 使用一个轻量级解码器处理聚合后的特征:解码器是一个具有单隐藏层(64个单元)和softplus激活函数的MLP。
混合表示的查询与输出:
- 这个混合表示可以对连续坐标进行查询,输出一个标量密度σ和一个32通道的特征。
- 然后,这些输出被神经体积渲染器处理,将3D特征体积投影到2D特征图像上。
体积渲染:
- 体积渲染使用了与NeRF中相同的方法实现。
- 特征图像的生成:在GAN框架中,体积渲染生成的是特征图像,而不是RGB图像。因为特征图像包含了更多信息,可以有效地用于后续的图像空间细化。
3.3 超分辨率 Super Resolution
虽然Tri-plane表示相比之前的方法在计算效率上有显著提升,但在高分辨率下直接进行训练或渲染仍然太慢。因此,作者选择在中等分辨率(如128×128)下执行体渲染,然后依靠图像空间的卷积操作将神经渲染结果上采样到最终的图像尺寸(256×256或512×512)。
超分辨率模块的设计:
- 结构:由两个包含StyleGAN2调制卷积层的模块组成,这些卷积层对32通道的特征图像 进行上采样和细化,生成最终的RGB图像 。
- 细节:禁用了每像素的噪声输入,以减少纹理粘连现象(texture sticking)。重用了骨干网络的映射网络来对这些卷积层进行调制。
3.4 双重判别 Dual Discrimination
在标准的2D GAN训练中,生成的图像通常由2D卷积判别器进行评判。作者使用了StyleGAN2的判别器,并进行了两个修改:
双重判别:解决先前工作中出现的多视图不一致问题。
将神经渲染的特征图像 的前三个特征通道解释为低分辨率的RGB图像 。
将 双线性上采样到与超分辨率图像 相同的分辨率。
将上采样后的 与 进行通道上的连接,形成一个六通道的图像输入判别器(见图4)。
对每个真实图像,生成一个适当模糊的副本,与原图像连接,形成六通道输入。
使判别器感知相机姿态:按照StyleGAN2-ADA中的条件生成策略,将渲染相机的内参和外参矩阵(统称为 (P))作为条件标签传递给判别器。
- 作用:这一条件输入为判别器提供了额外的信息,引导生成器学习正确的3D先验。
3.5 姿态条件化 pose-based conditioning
摄像机姿态与其他属性(例如面部表情)存在相关性。如果直接处理,可能会导致视图不一致的结果。例如,摄像机相对于人脸的角度与微笑可能存在相关性。
生成器的姿态条件化(Generator Pose Conditioning)
- 方法:在提供给生成器的映射网络时,除了潜码向量 (z) 外,还输入相机参数 (P),遵循条件生成策略。
- 作用:
- 通过让生成器知晓渲染相机的位置,使目标视角能够影响场景的合成。
- 在训练过程中,姿态条件化使生成器能够建模数据集中隐含的姿态依赖偏差,从而可靠地再现数据集中的图像分布。