TOP📢注意:本网站部署在 Github Pages 上,请科学上网!🏃♂️➡️
本网站同时还部署在

ZoomEye 学习笔记
https://arxiv.org/abs/2411.16044
本质上来说,这个工作应该就是 prompt engineering / agent,都是人为设定好的规则来 tree search 目标物体,是 training-free 的
Vstar 学习笔记
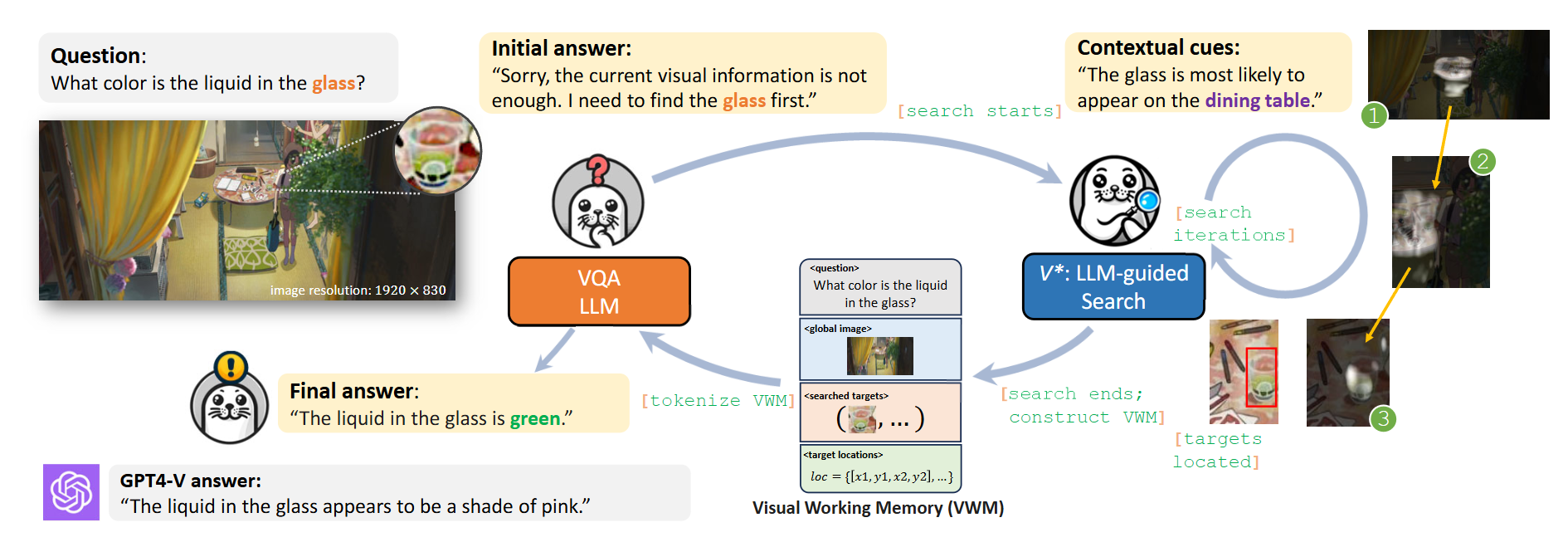
https://arxiv.org/abs/2312.14135
V* 感觉就类似于 agent
当前的多模态大模型(比如 LLaVA、GPT-4V 等)在处理复杂或高分辨率图像时,存在两个主要问题:
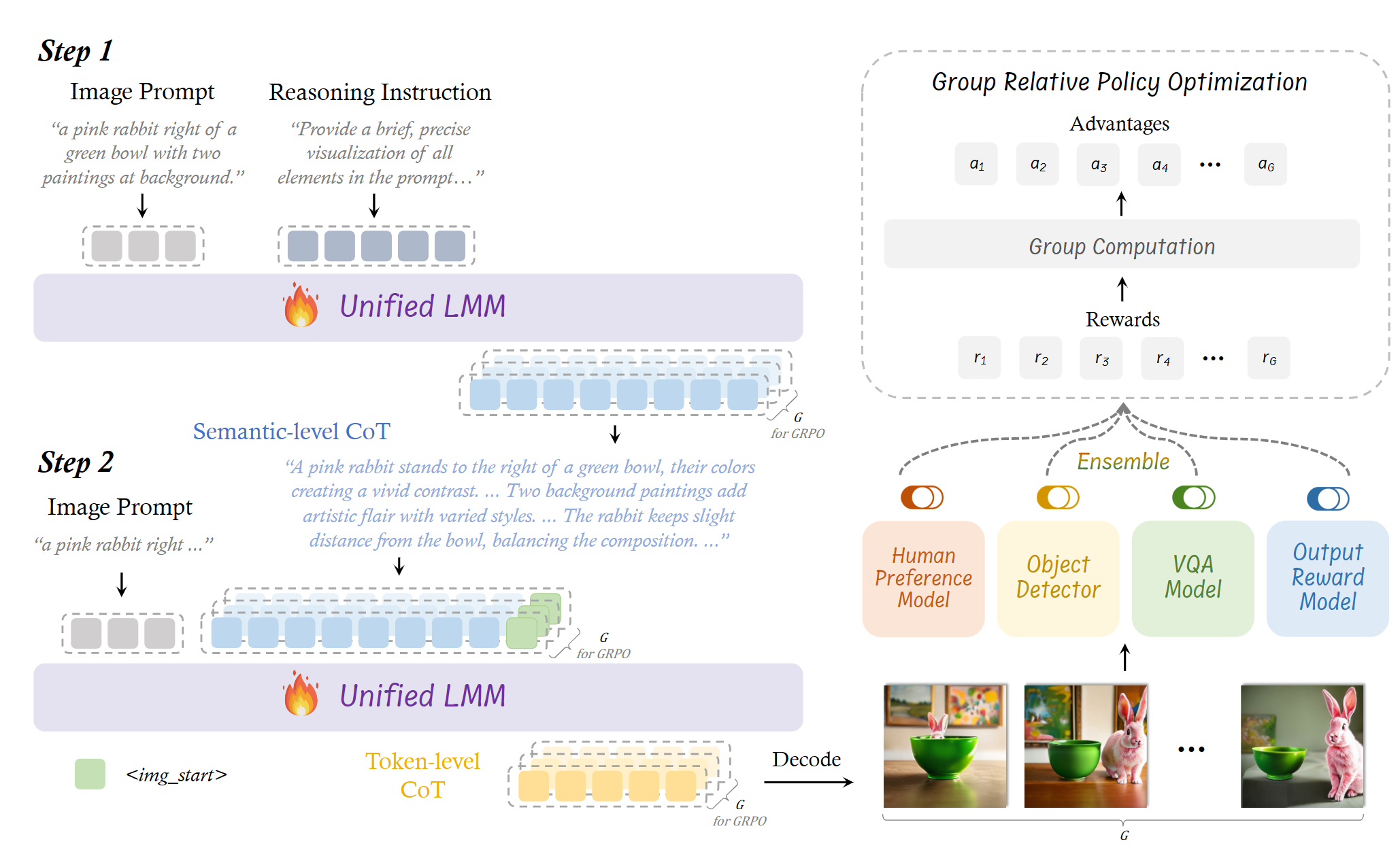
T2I-R1 学习笔记
https://arxiv.org/pdf/2505.00703
将语言模型中的 CoT 推理机制与 RL 方法引入图像生成领域
- 图像生成不仅需要理解文本(prompt)含义,还要实现跨模态的、逐像素的细节合成
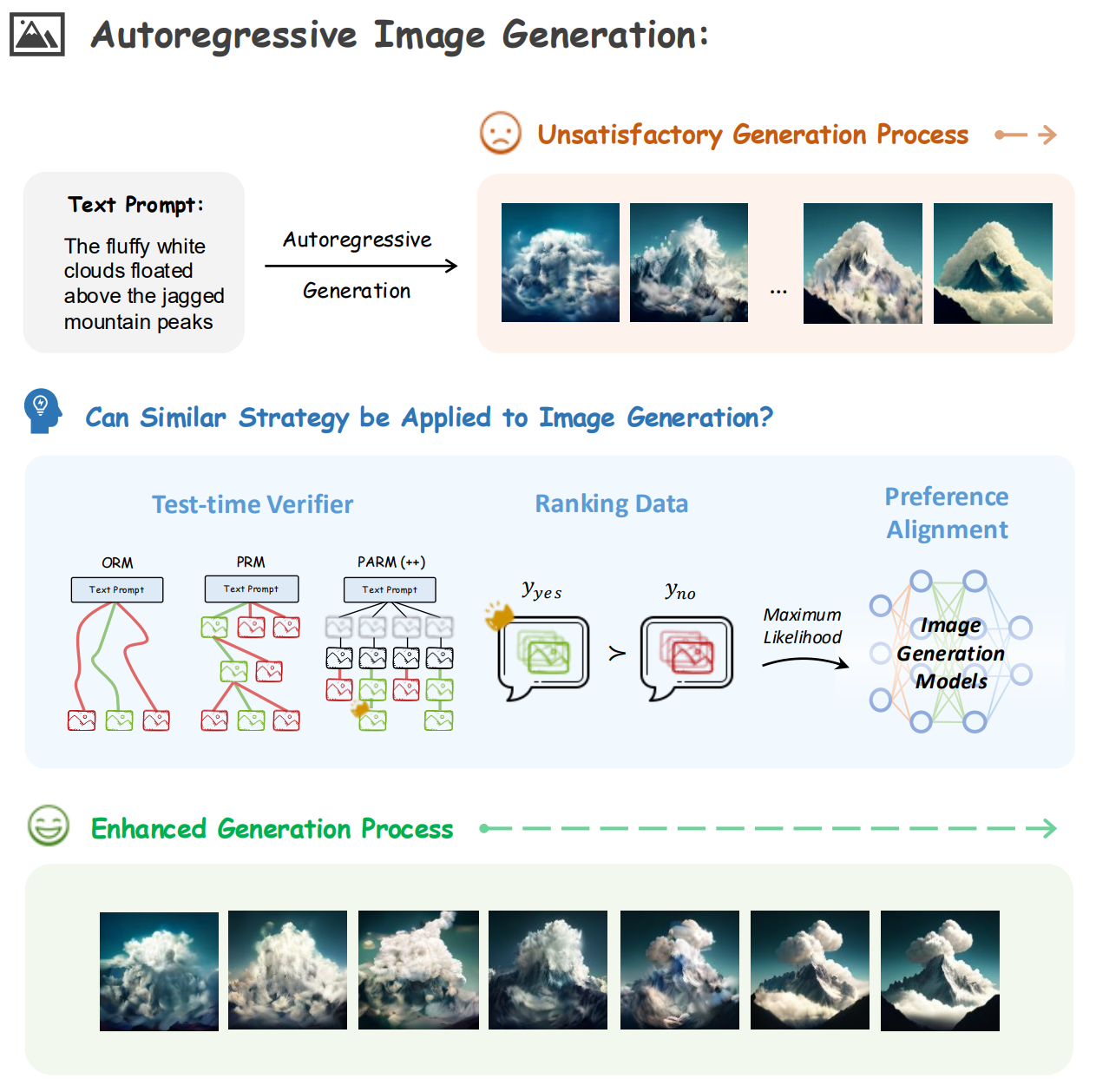
Can We Generate Images with CoT? 学习笔记
https://arxiv.org/abs/2501.13926
将 CoT 推理策略从语言任务迁移到自回归图像生成中
自回归图像生成与语言生成在“逐token生成”的机制上高度相似,为应用CoT提供了潜在可行性
Show-o 的图像生成方式本质上是一种基于 mask 的 iterative
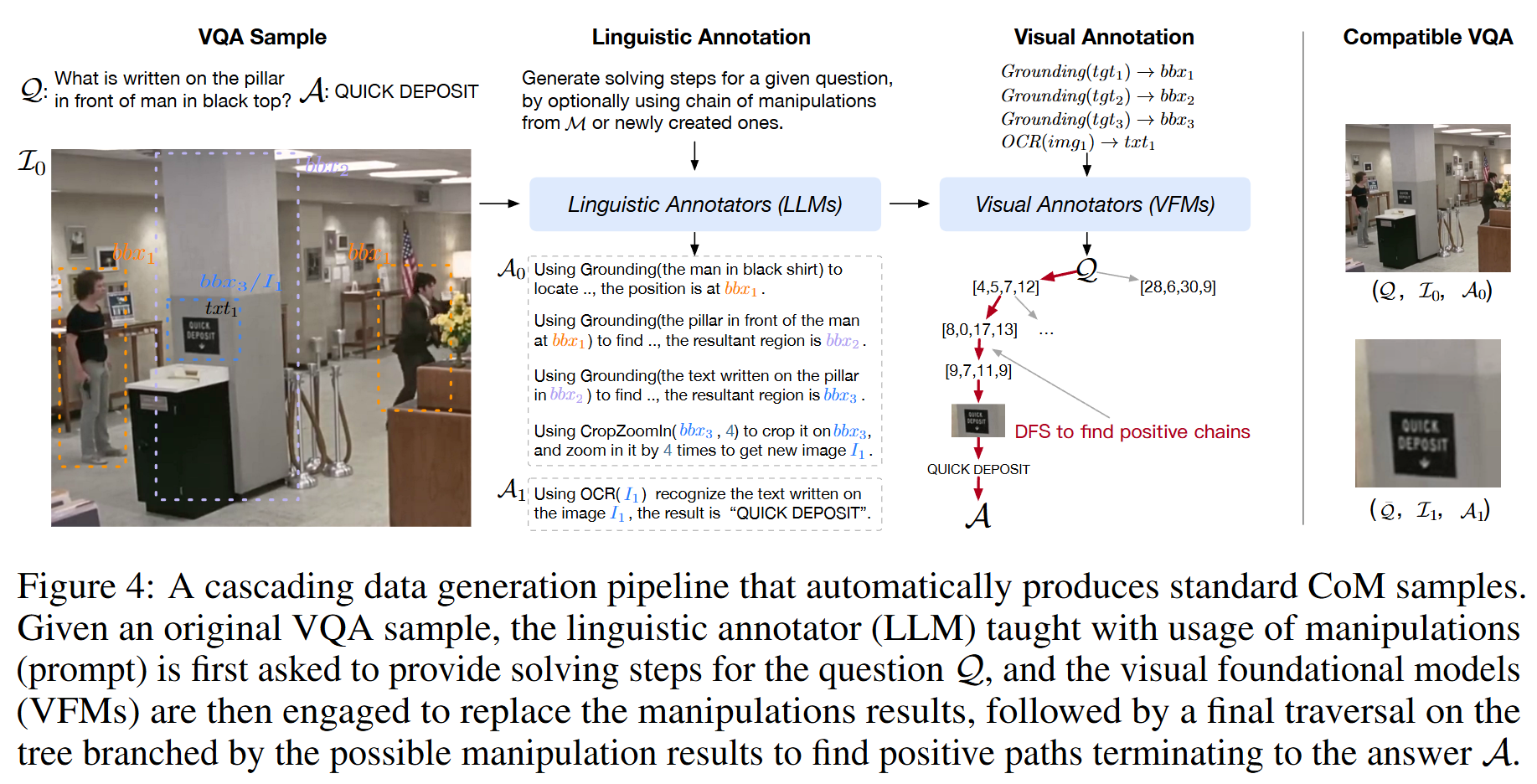
CogCoM 学习笔记
https://arxiv.org/abs/2402.04236
当前 VLMs 通过对齐视觉输入和语言输出训练,虽然整体表现好,但在需要细致视觉推理的任务上容易出错,比如无法正确识别图片中的细节内容。这是因为现有模型习惯直接给出结论,而缺乏中间推理步骤。
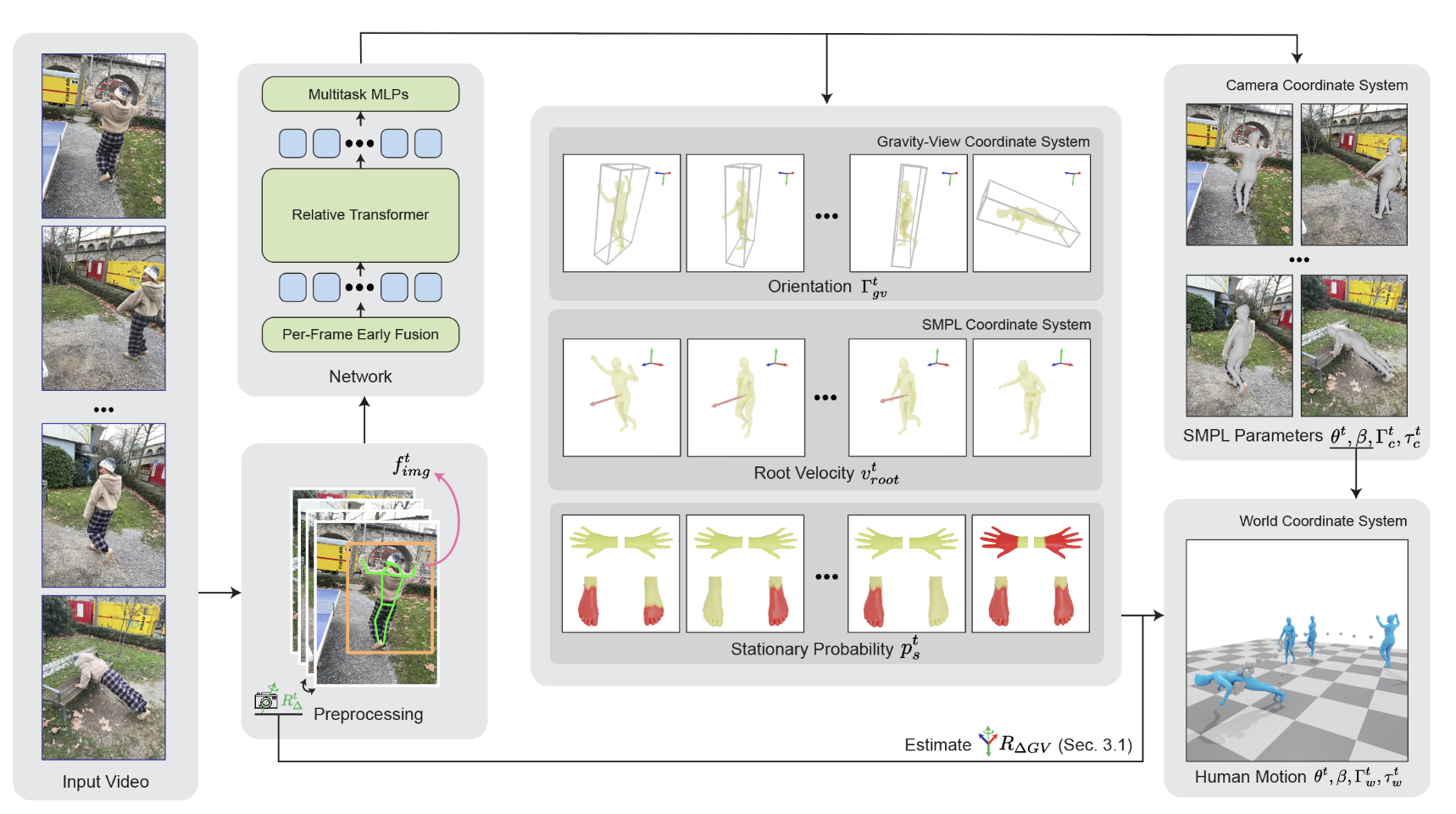
GVHMR 学习笔记
World-Grounded Human Motion Recovery (HMR):从单目视频中恢复世界坐标系下的人体动作,核心挑战在于世界坐标系的定义存在歧义,这在不同的视频序列之间可能会有所不同。
PLUS-WAVE 的 2024? 总结
虽然说是 2024 的总结,但是我从写博客开始就没有一个总结,不如趁着这个机会,我就将我从写博客起源开始,将我这接近两年的博客生涯,回顾总结一下吧!
Conda安装Pytorch和CUDA/GCC与一些环境Bug解决
在实验室服务器上的时候,一般是没有 root 权限的,而服务器可能只安装了特定版本的 CUDA 和 GCC,我们就需要自己安装自己需要版本的 CUDA/GCC 来满足安装包时的环境要求。
而 Conda 除了安装 Python 的包以外,其还提供了很多其他库——比如CUDA、GCC甚至还有 COLMAP
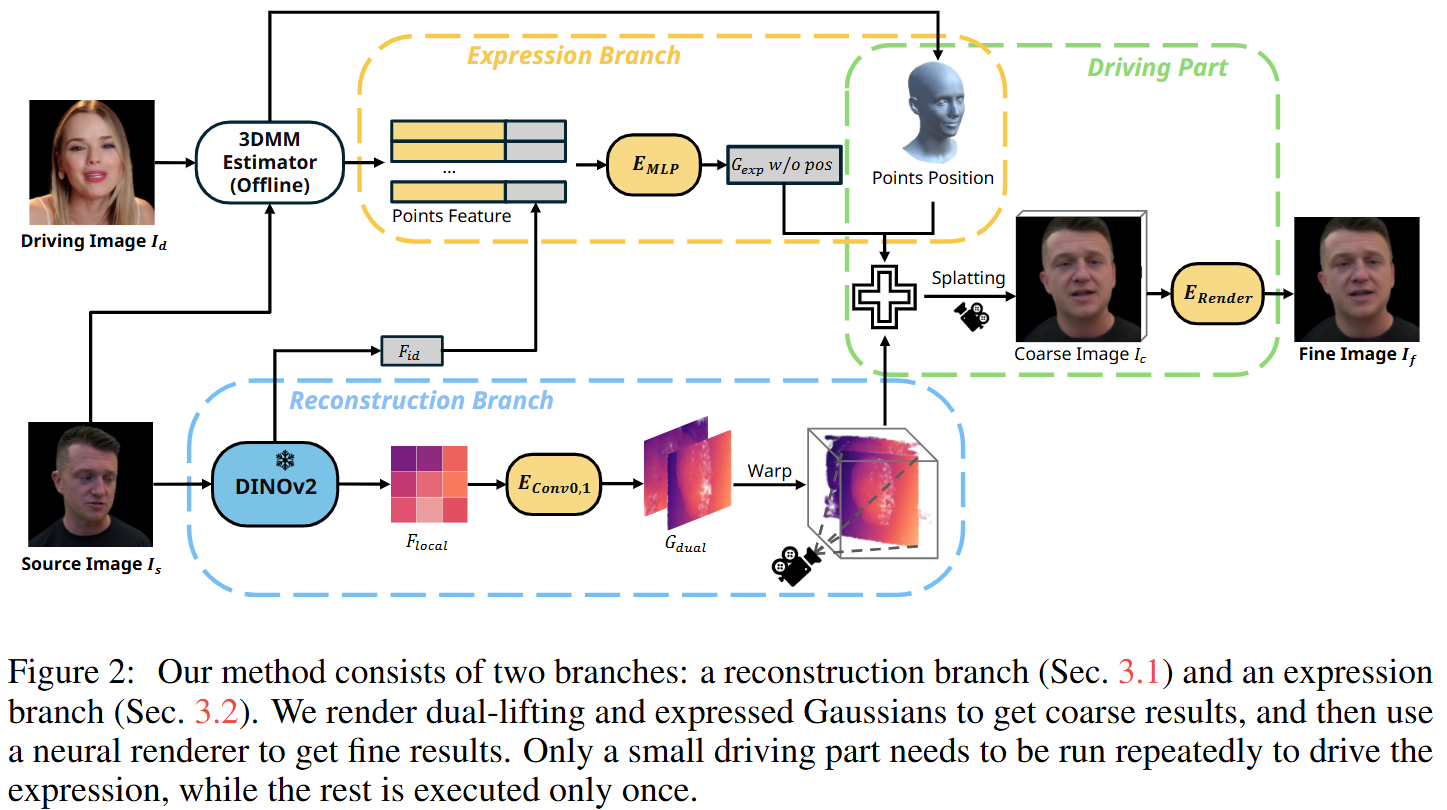
GAGAvatar 学习笔记
GAGAvatar(Generalizable and Animatable Gaussian Avatar),一种面向单张图片驱动的可动画化头部头像重建的方法,解决了现有方法在渲染效率和泛化能力上的局限。
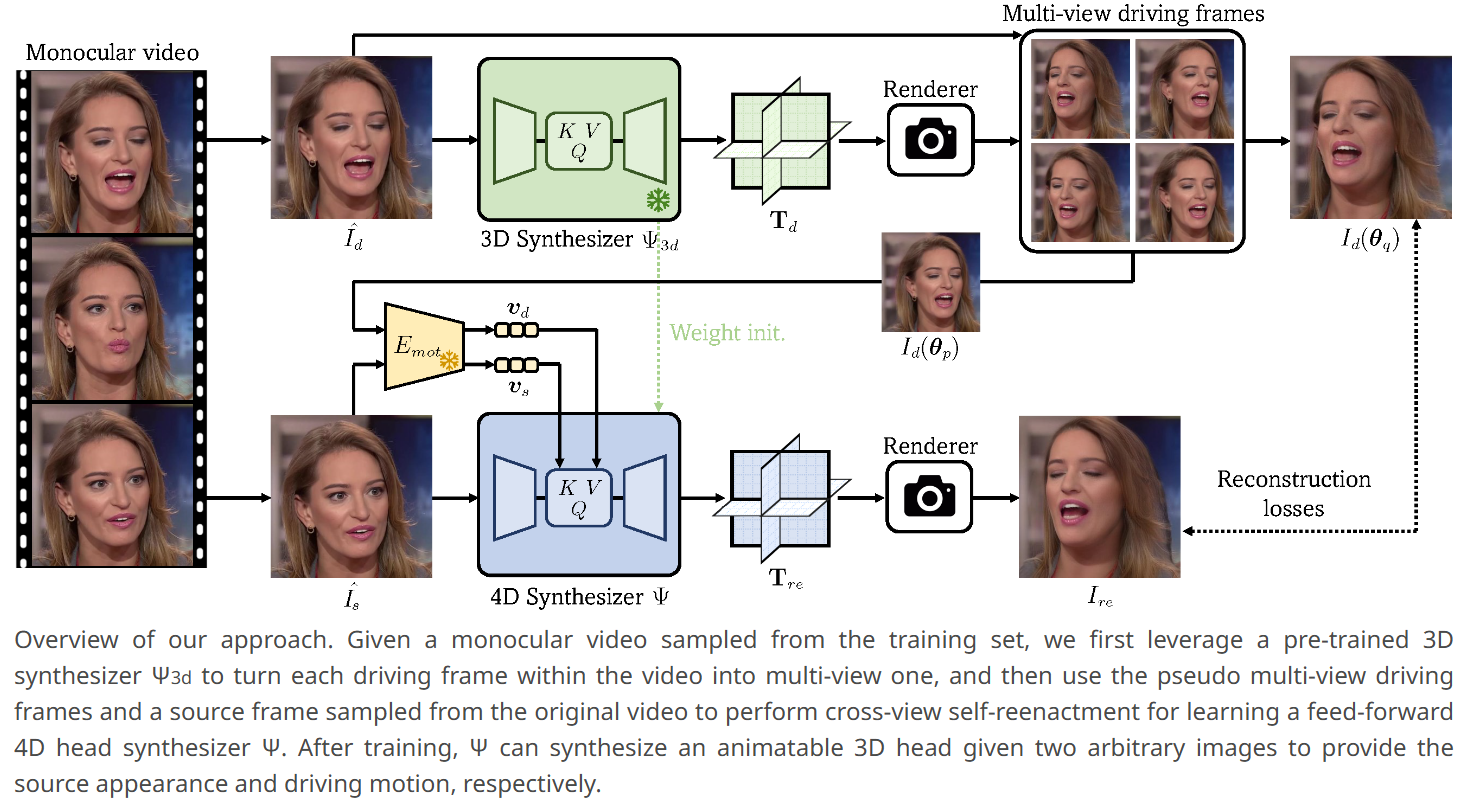
Portrait4D-v2 学习笔记
作者提出了一种基于伪多视角视频的学习框架,绕过了不准确的3DMM重建的高度依赖(Portrait4Dv1 的 Limitation),核心思路是:
- 伪多视角数据生成:从单目视频生成多视角数据
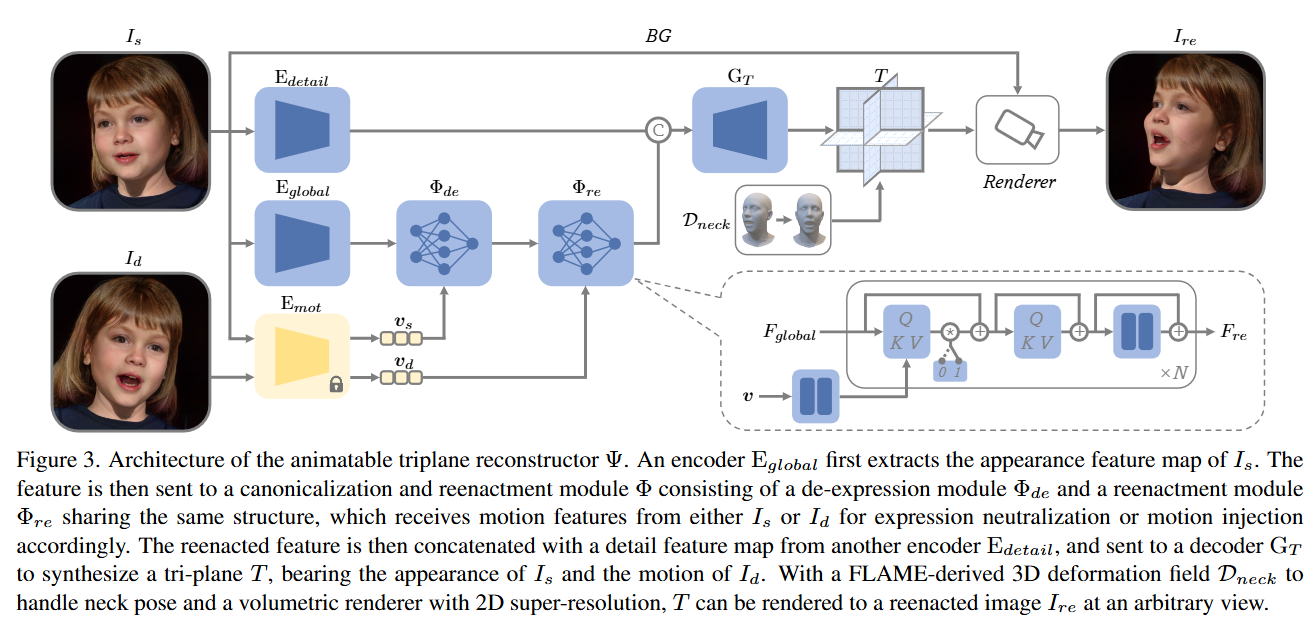
Portrait4D 学习笔记
- 目标:学习一个模型,能够从源图像 和驱动图像 中提取外观和动作信息,合成出具有 外观和 动作的3D人头。
- 3D表示:采用基于 Tri-plane 的 NeRF 作为底层的3D表示方式,兼具高保真度和高效率。
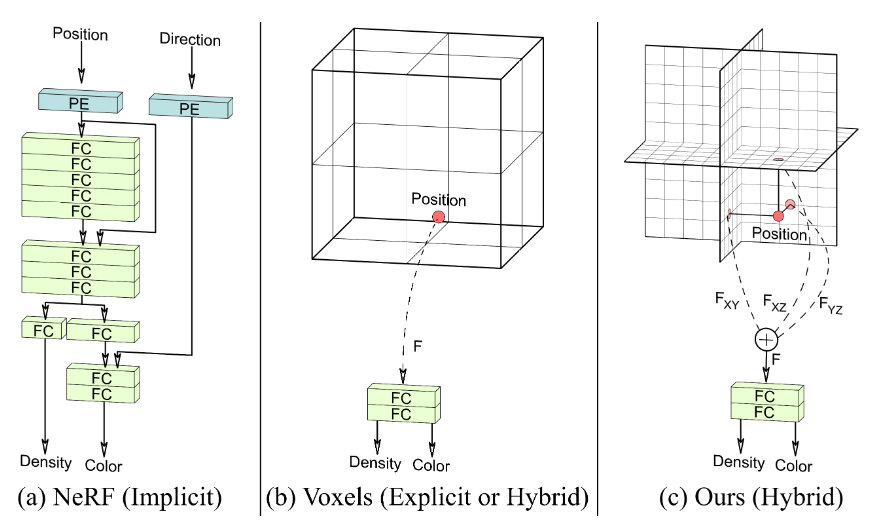
EG3D 学习笔记
-
混合显式-隐式网络架构:提出了一种 Tri-plane 的3D表征方法,结合显式体素网格与隐式解码器的优点
- 速度快,内存效率高;
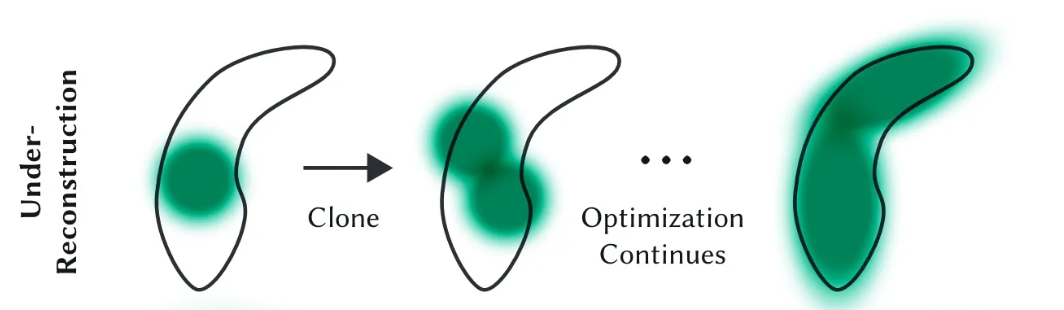
3DGS中Densification梯度累计策略的改进——绝对梯度策略(Gaussian Opacity Fields)
在学习 StreetGS 代码中发现了其中的 Densification 策略与原 3DGS 不太一样,其是使用的 Gaussian Opacity Fields 中的一个的策略
我们先来回忆一下 3DGS 中一个比较重要 contribution
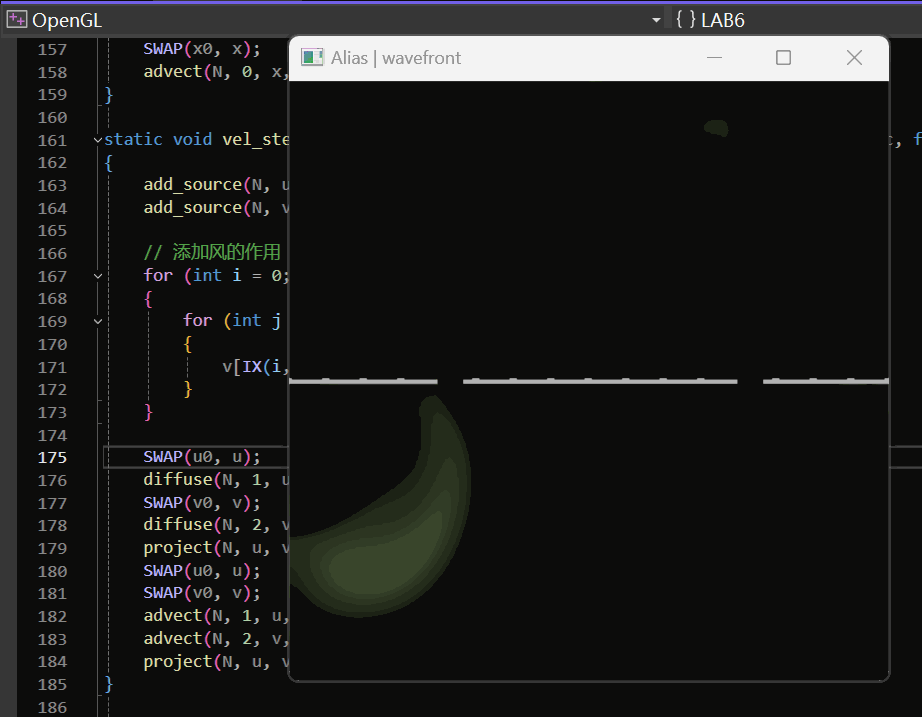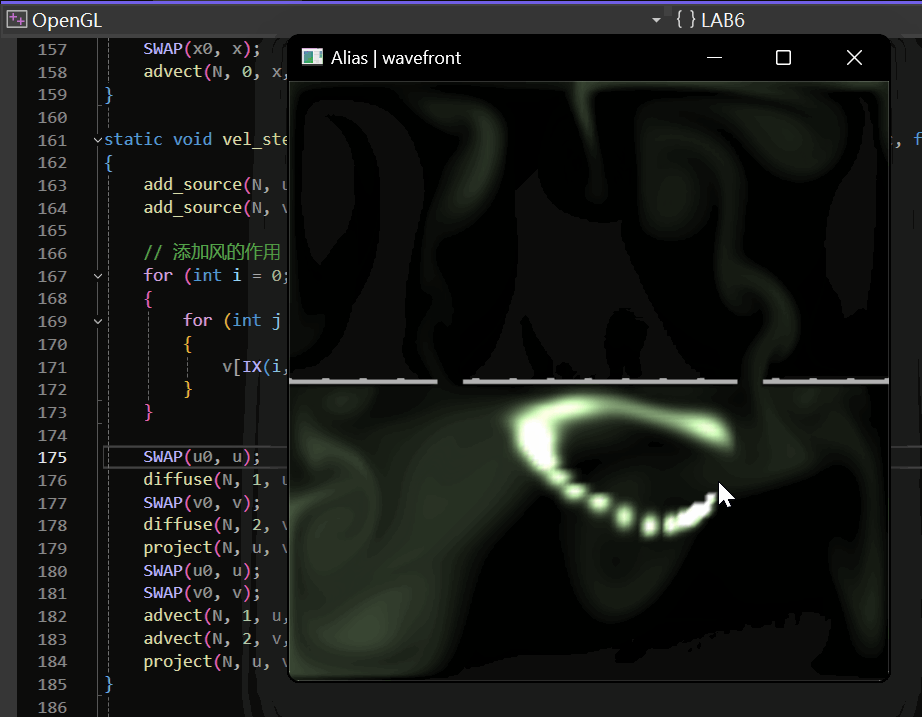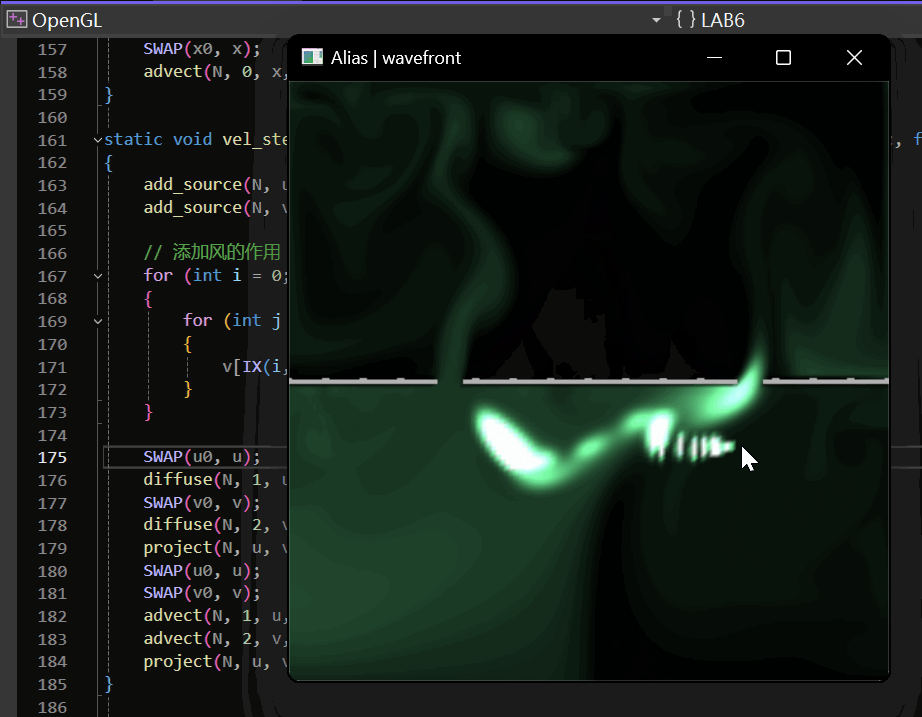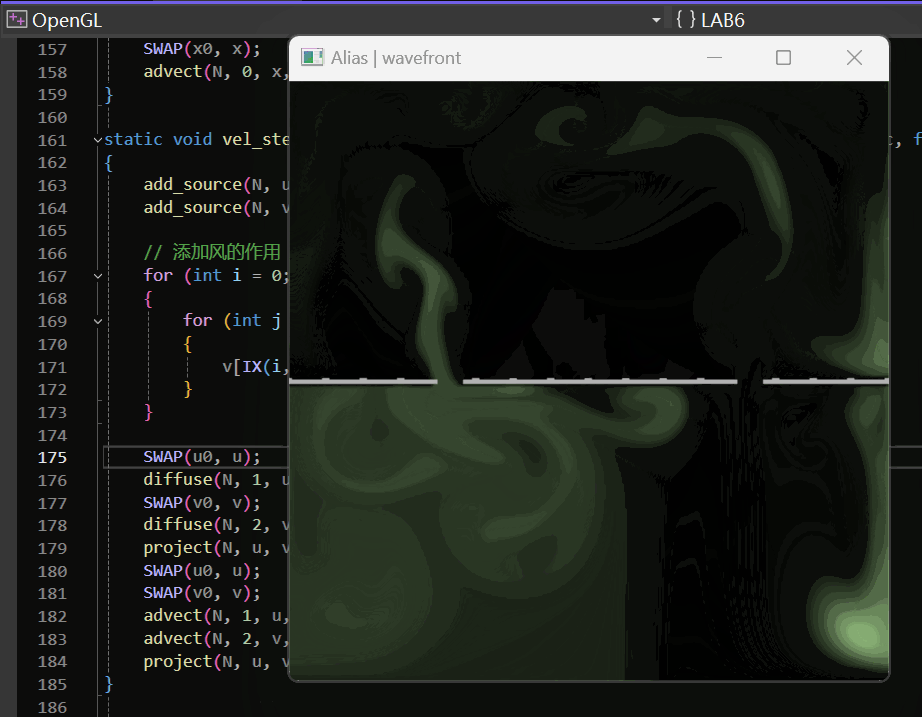
OpenGL/GLUT实践:流体模拟——数值解法求解Navier-Stokes方程模拟二维流体
源码见GitHub:A-UESTCer-s-Code
最终的实现效果如下:
